数据结构与算法
复杂度
时间复杂度:有限个常数操作的时间复杂度是O(1);N个量级的常数操作是O(N);NlogN个量级的常数操作是O(NlogN)【没有说明底数均为2】,以此类推
常数操作:固定时间内完成的与N无关的操作
时间复杂度分为
最差情况表现:没有特殊说明,时间复杂度都指最差情况下的算法表现
平均情况表现:工程上常用这个
最好情况表现
额外空间复杂度:除去本身的的样本N,额外还要占用的内存
局部变量的内存用一次释放一次,如for循环中单个循环定义的变量,一个循环完释放一次,下个循环重新开辟空间
master公式
可以用来计算递归调用的母问题的时间复杂度,具体的应用实例间递归求数组的最大值,master公式适用于同一层子问题等规模的情况
T(N)表示母问题的时间复杂度,N是母问题的数据量规模【数据规模可认为是数组的长度】;a表示同一层递归中子问题的递归方法调用次数【注意不是递归深度】;子问题的规模必须相等,T(N/b)就是子问题的时间复杂度,N/b是子问题的数据规模;O(N^d)是除去子问题队规调用外其余过程的时间复杂度
master公式的性质
对数器
对数器的作用
即使可以不依赖线上测试平台来确认自己的算法对错,相当于自己构建对数器来判断算法对错
对数器的构建
方法a是自己想要测试的方法,性能优异,但是难实现
方法b是好实现的方法但是算法性能不行【方法b就是对数器方法】
利用java的随机数
Math.random准备随机样本产生器【比如下面的随机数组】产生一份随机数组,copy出另一份完全一样的随机数组;两个方法均对相同的随机样本进行处理,用isEqual方法测试处理后两个数组的状况,对应位置元素有不一样的把差异信息打印出来对程序进行调试,测个几十万上百万次,只要都一样,就认为方法a完全没问题
常见小算法小结
随机数组
用于后续的排序测试,要求大小随机,数值随机,可以为负数,需要指定最大值和最大数组长度,
原理
Math.random() --> [0,1)的所有小数等概率返回一个
Math.random()*N --> [0,N)的所有小数等概率返回一个
(int) Math.random()*N --> [0,N-1]的所有整数等概率返回一个
代码实现
xxxxxxxxxxpublic class RandomUtil {private RandomUtil(){}public static int[] generateRandomArray(int maxSize,int maxValue){int[] randomArr=new int[(int)(Math.random()*(maxSize+1))];//数组长度随机for (int i=0;i<randomArr.length;i++){randomArr[i]=(int)(Math.random()*(maxValue+1))-(int)(Math.random()*(maxValue));//再减一个(int)(Math.random()*(maxValue)是为了产生随机负数}return randomArr;}}疑问
为什么减去的是(int)(Math.random()(maxValue)而不是(int)(Math.random()(maxValue+1))
异或运算小结
异或运算
^是位运算,位运算的运算规则是位运算符的两边的整数转成二进制,对应位进行位运算对应得到的值组成二进制再转化为十进制整数即为两整数位运算的结果
异或运算的规则
两个整数二进制形式对应位相同则对应二进制位结果为0,对应位不同则对应二进制位结果为1【可以理解成二进制各个位无进位相加】
异或运算的性质
性质1:
0^N=N、N^N=0【因为0和0异或为0,0和1异或为1】性质2:异或运算满足交换律和结合律
a^b=b^a、(a^b)^c=(a^(b^c))异或运算结合律的原因可以用无进位相加解释,二进制位奇数个1则结果为1,偶数个1则结果为0,即一个二进制位只与1的个数奇偶有关,与顺序无关,这个方法同样可以解释性质3和交换律
性质3:同一批数异或结果一定是一样的,与这批数的异或顺序无关
异或运算的运用
交换两个数的值:
原理是
b=a^b=(a^b)^b=a^0=a,a=a^b^a=b,相比传统交换两个数的值少节省一个内存xxxxxxxxxxpublic static void swap(int[] arr, int i, int j) {arr[i] = arr[i] ^ arr[j];//a=a^barr[j] = arr[i] ^ arr[j];//b=a^barr[i] = arr[i] ^ arr[j];//a=a^b}必须保证a和b指向的内存不是同一个内存才能用这种交换方式【如数组的i和j不相等】,因为a和b指向的地址相同,
a=a^b会因为a和b相等而直接等于0,b=a^b也会因为a和b都为0而直接等于0,固两数指向的内存地址相同会直接把数据洗成0【不需要考虑整数型常量池,因为整数型常量池是一个Integer数组,整数型常量池只对包装类有效】
问题1:数组中一种数出现奇数次,其他数出现偶数次,如何找出这一种数
答:给一个变量初始值0,循环用该变量去异或运算数组中的每一个数
问题2:数组中两种数(a和b)出现奇数次,其他出现偶数次,如何找出这两种数
答:用一个初始值0的变量去循环异或数组中的每一个数,最终得
a^b,因为a和b是两种数,所以a^b必不等于0即对应二进制至少有一位为1,一般选取最右侧的第一个1比如第八位【专门有算法算右边第一个1的位置】,为1意味着这一位a和b为异或关系,即一个为0一个为1;再用一个初始值为0的变量去异或第8位不为0或不为1的哪些数,异或结果就是两种数种的一种,用这个数再去异或(a^b),即可得到另一种数【核心是找到右边第一个1的位和筛选出对应位不为1或0的数,算法都在下方展示】
取二进制右边第一个为1的位置
常见面试题,答案是
eor&(~eor+1)这个结果自动返回int类型,不用管1在第几位,可以直接通过eor&(~eor+1)用判断一个数某一位是不是1来使用
假设一个数
eor=1010111100,对该数取反加1~eor+1=0101000100,再与原数进行与运算eor&(~eor+1)=0000000100【&运算是二进制位同时为1才为1】
判断一个数的某一位是不是1
常见面试题
原理:k这个数的二进制只有对应的目标二进制位为1,可以直接用
k&m != 0表示m的对应为1【因为与运算同为1结果才为1】,用k&m == 0表示m对应的位置为0【m对应位置不为1所有二进制位全为0】
二分法
二分法可以用于数据状况特殊用二分策略优化,同样可以优化
非零即1的的特殊问题,如构建排查系统,某个节点左右根据条件可以甩掉一边,就可以尝试使用二分策略
问题1:
判断有序数组中是否有某个指定值存在
思路1:直接暴力遍历整个数组【时O(N)】
思路2:使用经典二分法,找到数组中间元素和目标数判大小,找到包含目标数的一方再找到中间元素再判大小【时O(logN)】
问题2:
找出有序数组中满足大于等于指定值的最左侧元素的下标
思路:使用二分,找到中点元素,中点元素大于指定值选择数组左侧;中点元素小于指定值选择数组右侧。对选中区域重复上述过程,直到二分到区间只有一个元素【时O(logN)】
代码实现
二分法的终止条件有个坑点,多留意二分终止条件是怎么写的【要分情况】
如果是两边通过自加1和自减1向中间收,终止条件是left>=right
如果是经典二分不断选区间求中点收束,?
xxxxxxxxxx/*** @param value 指定值* @param arr 数组* @return int* @描述 找出有序数组中满足大于等于指定值的最左侧元素的下标* @author Earl* @version 1.0.0* @创建日期 2023/06/11* @since 1.0.0*/public static int findFirstBigThanValueIndexOfOrderedArray(int value,int[] arr){int index2=arr.length-1;if (index2==-1){log.info("数组"+arr+"长度为0");}int index1=0,midIndex=findMidIndex(index1,index2),target=-1;while(midIndex!=index1 && midIndex!=index2){midIndex=findMidIndex(index1,index2);//二分法一定要注意这个代码的位置,放上面可以保证最后剩两个数仍然可以再二分if (arr[midIndex]>=value){target=midIndex;index2=midIndex-1;//midindex放上面这儿一定不要写index=midindex,会导致直接循环失效}else{index1=midIndex+1;}//midIndex=findMidIndex(index1,index2);放这儿会导致最后一次二分失效,midindex和一个边界相等,但是和另一个边界差一}if (target==-1){log.info("数组中没有比"+value+"大的数");return -1;}return target;}
问题3:已知无序数组相邻两个数一定不等,求一个局部最小位置,且算法时间复杂度好于O(N)
思路
先判断首尾是不是局部最小,有一个是就直接返回
取中点判断是不是局部最小,如果不是,选取不满足局部最小的一侧重复取中点【因为首尾都不是局部最小,所以数组必然存在趋势拐点,否则最后一个值不可能大于倒数第二个;又因为相邻两个数由条件不相等,所以拐点两边导数必然相异,不满足局部最小的臆测必然延续了数组首尾的特点,相应的对应一侧必有拐点】
求数组片段中间位置下标
原理:
[a,b]下标范围内的数组中间下标为a+(b-a)/2,注意返回的中间下标当偶数个元素时返回前半段最后一个一般写法是
(a+b)/2,这种写法当数组长度较大的情况下可能发生溢出,溢出算出的mid可能为负,用a+(b-a)/2计算就不存在溢出,因为期间没有大于数组长度的部分存在,用位运算右移一位表示除以2会加速运算,即a+((b-a)>>1)【注意位运算的优先级很低】代码实现:
xxxxxxxxxx/*** @return int 奇数个返回中间下标,偶数个返回前半部分最后一个下标,返回-1表示数组范围格式不正确* @描述 找到数组片段的中间数的下标,* @author Earl* @version 1.0.0* @创建日期 2023/06/10* @since 1.0.0*/public static int findMidIndex(int startIndex,int endIndex){if (endIndex==-1){log.info("数组长度为0");}if (startIndex>endIndex){log.info("数组范围错误");return -1;}return startIndex+(endIndex-startIndex)/2;}
递归求数组的最大值
递归求数组最大值的时间复杂度和从左到右遍历求最大值的时间复杂度指标是一样的都是O(N)
思路
范围上只有一个数,直接返回该数作为数组的最大值
范围上不止一个数,则求出中点位置,调用自身分别求出左侧和右侧范围的最大值,返回两个值中的最大值【实际原理是利用递归将范围划分至一个数,两个数间两两比较返回大的值作为区间的最大值】
代码实现
xpublic static int getMax(int[] arr) {return process(arr, 0, arr.length - 1);}public static int process(int[] arr, int L, int R) {if (L == R) {return arr[L];}int mid = L + ((R - L) >> 1);int leftMax = process(arr, L, mid);int rightMax = process(arr, mid + 1, R);return Math.max(leftMax, rightMax);}时间复杂度:由master公式
递归求数组最大值的其他思路
分别求出左侧2/3和右侧2/3区间内的最大值,并取二者间的较大值作为最大值
时间复杂度
分别求出左中右侧的最大值,并取三者间的较大值作为最大值
时间复杂度
小和问题
核心是归并排序的merge方法中左侧比右侧小,小和累加【左侧数值】【右侧比左侧数值大的个数】,即arr[leftIndex](right-rightIndex+1);当左侧等于右侧时,右侧先拷贝,避免左侧相等的数无法被计算小和
数组中的小和
数组中一个元素左侧比当前元素小的数累加起来的和称为当前元素的小和,数组中所有元素的小和的累计和即为数组的小和
解决思路
直接暴力遍历,对每一个元素找出左侧比其小的所有数累加,然后把所有元素的小和累加
时间复杂度O(N2)
用归并排序对暴力遍历的方式进行改良
核心是归并排序期间,整合右边新发现的每一个数;对于左侧的每一个数,右侧每有一个数比其大就会新产生一个左侧对应数的小和,含义是发现了一个新的数如4比左侧的如1,3大,因此会产生1和3两个小和
注意求小和的merge方法,当左侧和右侧相等的时候一定要先拷贝右侧的数,此时不产生小和;当右侧的数比左侧更大时,拷贝左侧的数的同时计算小和
代码实现
【自己实现】
xxxxxxxxxxpublic static int smallSum(int[] arr,int left,int right){if (arr.length<2 || left==right){return 0;}int midIndex=left+((right-left)>>1);return smallSum(arr,left,midIndex)+smallSum(arr,midIndex+1,right)+merge(arr,left,midIndex,right);}public static int merge(int[] arr,int left,int midIndex,int right){int[] help=new int[right-left+1];int leftIndex=left;int rightIndex=midIndex+1;int helpIndex=0;int res=0;while (leftIndex<=midIndex && rightIndex<=right){res+=arr[leftIndex]<arr[rightIndex]?arr[leftIndex]*(right-rightIndex+1) :0;help[helpIndex++]=arr[leftIndex]<arr[rightIndex]?arr[leftIndex++] :arr[rightIndex++];}while (leftIndex<=midIndex){help[helpIndex++]=arr[leftIndex++];}while (rightIndex<=right){help[helpIndex++]=arr[rightIndex++];}for (int i = 0; i < help.length; i++) {arr[left+i]=help[i];}return res;}【左神实现】
xxxxxxxxxxpublic static int smallSum(int[] arr) {if (arr == null || arr.length < 2) {return 0;}return mergeSort(arr, 0, arr.length - 1);}public static int mergeSort(int[] arr, int l, int r) {if (l == r) {return 0;}int mid = l + ((r - l) >> 1);return mergeSort(arr, l, mid) //累加左侧的小和+ mergeSort(arr, mid + 1, r) //累加右侧的小和+ merge(arr, l, mid, r);//累加左右侧合并过程中产生的小和}public static int merge(int[] arr, int l, int m, int r) {int[] help = new int[r - l + 1];int i = 0;int p1 = l;int p2 = m + 1;int res = 0;while (p1 <= m && p2 <= r) {//当两边范围都有可以合并的数时res += arr[p1] < arr[p2] ? (r - p2 + 1) * arr[p1] : 0;//左边的数比右边小,累加计算小和(r - p2 + 1) * arr[p1]【计算的是右边剩余个数*左边的数】help[i++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];//当左侧比右侧小时,左侧先拷贝;当右侧和左侧相等或者右侧小于左侧时,右侧先拷贝}while (p1 <= m) {help[i++] = arr[p1++];}while (p2 <= r) {help[i++] = arr[p2++];}for (i = 0; i < help.length; i++) {arr[l + i] = help[i];}return res;}
逆序对
小和问题是找左端比右端小的数,逆序对是找左端比右端大的数并利用下标快速计数
逆序对:数组中左边的数比右边的数大,则这两个数构成一个逆序对;找出数组中所有逆序对的数量
思路:和小和问题是类似的,只是换成了右边比左边小的时候计数+1,直接把数组反转就变成了典型小和问题的变形
代码实现:
【自己实现】
xxxxxxxxxxpublic class ReversePair {public static int reversePair(int[] arr){ArrayUtils.reverseArray(arr);int right=arr.length-1;return getReversePair(arr, 0, right);}public static int getReversePair(int[] arr,int left,int right){if (arr==null || arr.length<2 || right==left){return 0;}int midIndex=left+((right-left)>>1);return getReversePair(arr,left,midIndex)+getReversePair(arr,midIndex+1,right)+merge(arr,left,midIndex,right);}public static int merge(int[] arr,int left,int midIndex,int right){int[] help=new int[right-left+1];int leftIndex=left;int rightIndex=midIndex+1;int helpIndex=0;int res=0;while(leftIndex<=midIndex && rightIndex<=right){res+=arr[leftIndex]<arr[rightIndex]?right-rightIndex+1:0;help[helpIndex++]=arr[leftIndex]<arr[rightIndex]?arr[leftIndex++]:arr[rightIndex++];}while(leftIndex<=midIndex){help[helpIndex++]=arr[leftIndex++];}while(rightIndex<=right){help[helpIndex++]=arr[rightIndex++];}for (int i = 0; i < help.length; i++) {arr[left+i]=help[i];}return res;}}
荷兰国旗问题
问题描述【注意没有规定数组中小于和大于num的区域要有序】
问题1:给定一个数组和一个指定数num,处理后数组左边都小于等于num,数组右边都大于num
问题2:给定一个数组和一个指定数num,处理后左边都小于num,中间都等于num,右边都大于num
解题思路
问题1思路:假设一个小于等于区,
下文都用≤区表示,初始时≤区的下标从-1开始,从左到右依次遍历数组的每个值arr[i],若arr[i]<=num,则与≤区的下一个元素互换,≤区右扩一格;若arr[i]>num,只执行i++,其他不变【等同于用互换以及满足条件≤区自动扩大一格,≤区推着>区走】问题2思路:假设有两个区域
<区和>区,若
arr[i]<num,arr[i]和<区下一个交换,交换后<区后扩1,且i++若
arr[i]=num,仅i++若
arr[i]>num,arr[i]和>区下一个交换,交换后>区左扩1,i原地不变【因为换了一个未知大小的数字到i处,需要重新判断位置】【实质是用小于区和大于区压缩等于区和待定区,当等于区撞上大于区就完成问题2】
排序算法
选择排序
原理:数组arr从0-N选出最小值与下标为0元素互换,接着从1-N选出最小值和1元素互换,以此类推直到N-N
核心是每次把当前最小的数一次交换移到最左边
时间复杂度:O(N2)【每次内循环比较了N-i次,外循环执行了N次,总共比较次数是二元函数】;
额外空间复杂度O(1)
代码实现
【本人实现】
xxxxxxxxxxpublic class SelectedSort {public static void selectedSort(int[] arr){if (arr==null || arr.length<2){//注意这里不加arr==null的判断可能会出现空指针异常,左神牛逼return;}for (int i=0;i<arr.length;i++){int minValueIndex=i;//minValueIndex接收内层遍历最小值的下标for (int j=i;j<arr.length;j++){minValueIndex=arr[minValueIndex]<arr[j]?minValueIndex:j;//如果当前元素比当前最小值小,把当前元素下标赋值给minValueIndex}swap(arr,i,minValueIndex);//内层遍历第一个元素与本次遍历最小值位置互换}}//数组元素互换方法swap,注意必须定义成静态方法,因为静态方法调用实例方法必须通过引用调用,而静态方法调用静态方法可以省略类名private static void swap(int[] arr,int fromIndex,int toIndex){int temp=arr[fromIndex];arr[fromIndex]=arr[toIndex];arr[toIndex]=temp;}}【左神实现】
xxxxxxxxxxpublic static void selectionSort(int[] arr) {if (arr == null || arr.length < 2) {return;}for (int i = 0; i < arr.length - 1; i++) {int minIndex = i;for (int j = i + 1; j < arr.length; j++) {minIndex = arr[j] < arr[minIndex] ? j : minIndex;}swap(arr, i, minIndex);}}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}
冒泡排序
原理:第一次
0-N上从左到右两两比较,大的应该在右边,从而让最大值在数组最右边;第二次0-(N-1)上从左到右重复上述过程,直到0-0核心是单次循环把最大值两两比较保持最大值在右边,最后本次循环最大值在本次循环的最右边
时间复杂度:O(N2)【每次内循环比较了N-i次,外循环执行了N次,总共比较次数是二元函数】;
额外空间复杂度O(1)【单次循环有限变量】
代码实现
【本人实现】
xxxxxxxxxxpublic class BubbleSort {public static void bubbleSort(int[] arr){log.info("bubbleSorting...");if (arr==null || arr.length<2) {return;}for (int i=arr.length-1;i>=0;i--){for (int j=0;j<i;j++){//单次循环最大的放最右边if (arr[j]>arr[j+1]){//相邻两个数大的应该在右边,否则大的右移swap(arr,j,j+1);}}}}public static void swap(int[] arr,int fromIndex,int toIndex){int temp=arr[fromIndex];arr[fromIndex]=arr[toIndex];arr[toIndex]=temp;}}【左神实现】
xxxxxxxxxxpublic static void bubbleSort(int[] arr) {if (arr == null || arr.length < 2) {return;}for (int e = arr.length - 1; e > 0; e--) {for (int i = 0; i < e; i++) {if (arr[i] > arr[i + 1]) {swap(arr, i, i + 1);}}}}public static void swap(int[] arr, int i, int j) {arr[i] = arr[i] ^ arr[j];arr[j] = arr[i] ^ arr[j];arr[i] = arr[i] ^ arr[j];}
插入排序
插入排序比选择和冒泡排序稍好就是因为时间复杂度上的区别,插入最差O(N2),其他两个稳定O(N2)
原理:像斗地主摸牌理牌一样,判断下标2的元素在1-2区间上是否满足大小位置合适【即
arr[2]>=arr[1]】,不满足2号元素左移直至其左边元素小于等于该元素;同理依次比较移动3、...、k直到N,排序完成时间复杂度:O(N2)【插入排序数据状况不同,时间复杂度是不同的,不像选择排序和冒泡排序是固定的,最坏的情况是
7、6、5、4、3、2、1此时是O(N2),最好的情况是1、2、3、4、5、6、7,此时是O(N)】;额外空间复杂度O(1)【单次循环有限变量】
代码实现
【自己实现】
xxxxxxxxxxpublic class InsertionSort {public static void insertionSort(int[] arr){log.info("insertionSorting...");if (arr==null || arr.length<2){return;}for (int i=1;i<arr.length;i++){//取1-i范围for (int j = i; j > 0; j--) {//j从i-1顺序遍历if (arr[j]<arr[j-1]){//如果j下标元素小于j-1下标元素,j号和j-1号互换位置【优化点】swap(arr,j,j-1);}}}}public static void swap(int[] arr,int fromIndex,int toIndex){arr[fromIndex]=arr[fromIndex]^arr[toIndex];arr[toIndex]=arr[fromIndex]^arr[toIndex];arr[fromIndex]=arr[fromIndex]^arr[toIndex];}}【左神实现】
xxxxxxxxxxpublic static void insertionSort(int[] arr) {if (arr == null || arr.length < 2) {return;}for (int i = 1; i < arr.length; i++) {for (int j = i - 1; j >= 0 && arr[j] > arr[j + 1]; j--) {//这儿可以把判断移到这儿来,简化代码;for循环条件不满足会直接跳出循环,这样会提升效率,少了很多无效循环和比较swap(arr, j, j + 1);}}}public static void swap(int[] arr, int i, int j) {arr[i] = arr[i] ^ arr[j];arr[j] = arr[i] ^ arr[j];arr[i] = arr[i] ^ arr[j];}
归并排序
归并排序的核心是先实现左侧和右侧的各自有序,单次merge产生的比较结果以局部有序的形式保存了起来,后面还可能会使用到,本质上是单次比较信息被复用,有点空间换时间的味道
原理
用递归方法mergeSort将数组划分至最小单元【即都只有一个数】,实际排序是在merge方法中一路局部有序排上来的【merge方法的逻辑:准备一个对应长度的辅助数组,用两指针指向数组两边范围的0号下标,比较下标所在的元素值,小的先拷贝入数组;相等的情况下,默认拷贝左边数组;拷贝一位,指针右移一位】
递归只起到划分作用,所有的排序都在merge方法中完成的
时间复杂度
额外空间复杂度
O(N):归并排序的外排序方法额外准备了一个数组,每次用完立马就释放了,最大准备的空间是N个空间
代码实现
自己实现
xxxxxxxxxxpublic class MergeSort {public static void mergeSort(int[] arr,int left,int right){if (arr=null || arr.length<2 || left==right){return;}int midIndex=left+((right-left)>>1);mergeSort(arr,left,midIndex);mergeSort(arr,midIndex+1,right);merge(arr,left,midIndex,right);}public static void merge(int[] arr,int left,int midIndex,int right){int[] help=new int[right-left+1];int leftIndex=left;int rightIndex=midIndex+1;int helpIndex=0;while (leftIndex<=midIndex && rightIndex<=right){help[helpIndex++]=arr[leftIndex]<=arr[rightIndex]?arr[leftIndex++] :arr[rightIndex++];//注意两个数相等的情况下,先放左边的,这样能保持排序的稳定性,但是小和问题这里只能写小于,才不会在等于的情况下左侧小和还没计算就被拷贝了}while (leftIndex<=midIndex){help[helpIndex++]=arr[leftIndex++];}while (rightIndex<=right){help[helpIndex++]=arr[rightIndex++];}for (int i = 0; i < help.length; i++) {arr[left+i]=help[i];}}}【左神实现】
xxxxxxxxxxpublic static void mergeSort(int[] arr) {if (arr == null || arr.length < 2) {return;}mergeSort(arr, 0, arr.length - 1);}public static void mergeSort(int[] arr, int l, int r) {if (l == r) {return;}int mid = l + ((r - l) >> 1);mergeSort(arr, l, mid);mergeSort(arr, mid + 1, r);merge(arr, l, mid, r);}public static void merge(int[] arr, int l, int m, int r) {int[] help = new int[r - l + 1];int i = 0;int p1 = l;int p2 = m + 1;while (p1 <= m && p2 <= r) {help[i++] = arr[p1] <= arr[p2] ? arr[p1++] : arr[p2++];//经典归并是有等于的,保证等于的情况下也是左侧的先被拷贝以维持排序稳定性}while (p1 <= m) {help[i++] = arr[p1++];}while (p2 <= r) {help[i++] = arr[p2++];}for (i = 0; i < help.length; i++) {arr[l + i] = help[i];}}
快排
原理
快排1.0:拿最后一个值当做num进行值划分分出≤区和>区,做完一次值划分就拿num和>区的第一个交换且
≤区扩充一格,大于区重复递归至没有大于区,≤区以倒数第二个值为num【因为倒数第一个值为前一个num,且区域内无序】重复递归至没有小于区;快排2.0:拿到最后一个值作为num进行值划分,让最后的num与
>区的第一个交换;<区和>区如法再递归至没有<区或>区,快排2.0比快排1.0略快,因为每次都能搞定一批
快排1.0和快排2.0的时间复杂度都是O(N2),可以通过列举最差的例子
1,2,3,4,5,6,7,8,9【每次划分都只解决最后一个数,但是没划分一次就要把其他的数都跑通,就是把划分值故意打偏,好情况是划分值刚好打在中间位置,此时左边和右边的规模差不多,近似可用master方法评估时间复杂度为O(N*logN),快排2.0无法避免差情况,因为每次都直接选最后一个】快排3.0:随机选一个数字放在最后做划分值,随机选中的概率为1/N,可能打在1/3、1/5处等等,用每种情况的时间复杂度*1/N,最后可以推导出快排3.0的时间复杂度为O(NlogN)
实现:
base case如果左边界大于右边界则直接返回,因为左边界和右边界是根据值划分的返回值确定的,可能存在没有大于区或者小于区的情况,不限定这个base case可能会导致无限递归【这个baseCase的含义其实就是没有小于区或者大于区,也是递归的终止条件】
在范围上随机一个数和最后一个数交换位置作为指定值
根据指定值进行一次值划分,返回等于区的左边界和右边界
对
<区和>区重复递归至没有小于区或者大于区
快排3.0代码实现
【自己实现】
xxxxxxxxxxpublic class QuickSort {public static void quickSort(int[] arr){if (arr==null || arr.length<2){return;}quickSort(arr,0,arr.length-1);}public static void quickSort(int[] arr,int left,int right){if (left>right){//这儿一定要注意快排递归base case,否则爆栈,不能写等于,可能没有大于区,没有大于区partition[1]+1会比right大return;}swap(arr,left+(int)Math.random()*(right-left+1),right);int[] partition = partition(arr, left, right);quickSort(arr,left,partition[0]-1);quickSort(arr,partition[1]+1,right);//没有大于区partition[1]+1会比right大}public static int[] partition(int[] arr,int left,int right){int less=left-1;int more=right;while(left<more){if (arr[left]<arr[right]){swap(arr,++less,left++);}else if (arr[left]>arr[right]){swap(arr,--more,left);}else {left++;}}swap(arr,more,right);return new int[] {less+1,more};}public static void swap(int[] arr,int from,int to){int temp=arr[from];arr[from]=arr[to];arr[to]=temp;}}【左神实现】
xxxxxxxxxxpublic static void quickSort(int[] arr) {if (arr == null || arr.length < 2) {return;}quickSort(arr, 0, arr.length - 1);}public static void quickSort(int[] arr, int l, int r) {if (l < r) {swap(arr, l + (int) (Math.random() * (r - l + 1)), r);//在当前快排的区间中随机选择一个和区间末尾的元素交换位置int[] p = partition(arr, l, r);//值划分返回的是一个数组,包含信息quickSort(arr, l, p[0] - 1);quickSort(arr, p[1] + 1, r);}}public static int[] partition(int[] arr, int l, int r) {int less = l - 1;int more = r;//下标r就是值划分的指定值,是之前随机出来的元素和r交换了位置while (l < more) {//当等于区没有遇到大于区时一直循环if (arr[l] < arr[r]) {//如果当前值小于指定值,则小于区扩展一位,小于区刚扩展的一位和当前值交换位置,完事l自加1swap(arr, ++less, l++);} else if (arr[l] > arr[r]) {//如果当前值大于指定值,则大于区左扩一位,刚刚左扩的一位和当前位置交换位置,完事继续判断刚刚交换过来的当前位置swap(arr, --more, l);} else {//如果当前值等于指定值,则当前值不管,下标l自加1l++;}}swap(arr, more, r);//将指定值和大于区第一个交换位置,并将大于区第一个位置在下一步划归至等于区return new int[] { less + 1, more };//返回值划分信息,返回的是等于区的左边界和有边界}public static void swap(int[] arr, int i, int j) {int tmp = arr[i];arr[i] = arr[j];arr[j] = tmp;}
堆排序
xxxxxxxxxxpublic static void heapSort(int[] arr) { if (arr == null || arr.length < 2) { return; } for (int i = 0; i < arr.length; i++) { heapInsert(arr, i); } int size = arr.length; swap(arr, 0, --size); while (size > 0) { heapify(arr, 0, size); swap(arr, 0, --size); }}
public static void heapInsert(int[] arr, int index) { while (arr[index] > arr[(index - 1) / 2]) { swap(arr, index, (index - 1) /2); index = (index - 1)/2 ; }}
public static void heapify(int[] arr, int index, int size) { int left = index * 2 + 1; while (left < size) { int largest = left + 1 < size && arr[left + 1] > arr[left] ? left + 1 : left; largest = arr[largest] > arr[index] ? largest : index; if (largest == index) { break; } swap(arr, largest, index); index = largest; left = index * 2 + 1; }}
public static void swap(int[] arr, int i, int j) { int tmp = arr[i]; arr[i] = arr[j]; arr[j] = tmp;}
排序的稳定性
定义:数组中数值相等的一批数排序前后的相对顺序没有改变
应用:排序的稳定性对基础类型数据没有啥作用,但是对非基础数据很有用
如学生有班级和年龄两个属性,按照年龄排序后再按照班级排序,班级排好序后同一个班级的学生年龄就是排好序的
又比如在保持商品排序的基础上好评率也是排好序的
几种排序方法的稳定性:
选择排序做不到稳定性,因为单次遍历的最小值和首位直接交换位置
冒泡排序可以做到稳定性,因为遇到相等的就不交换能保持同一种数前后顺序不变
插入排序可以做到稳定性,因为小就左移但遇到相等的就停下
归并排序可以做到稳定性,因为merge方法遇见小的会先拷贝左边数组的就保证了前后顺序不变【但是小和问题先拷贝右边的,所以小和问题的merge没有保持稳定性】
快排【一般快排都指的是随机快排3.0】做不到稳定性,因为划分值的过程会将满足条件的值直接和
<区后一位或者>区前一位直接交换,直接破坏了稳定性堆排也做不到稳定性,因为如
5、4、4、6,在heapinsert中6会和4直接交换位置,破坏稳定性计数排序和基数排序都能做到稳定性,核心是因为维持先入桶的先出桶从而保证了排序稳定性
排序大总结
| 排序方式 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| 选择 | O(N2) | O(1) | ✘ |
| 冒泡 | O(N2) | O(1) | ✔ |
| 插入 | O(N2) | O(1) | ✔ |
| 归并 | O(N*logN) | O(N) | ✔ |
| 快排 | O(N*logN) | O(logN) | ✘ |
| 堆排 | O(N*logN) | O(1) | ✘ |
要点:
一般排序都会选快排,虽然时间复杂度指标上和堆排是一样的,但是实际测试快排总是略快
常数项更低,速度最快;但是空间复杂度做不到O(1),稳定性也做不到
堆排一般用于空间有限制的时候
空间使用低,做不到稳定性
归并排序在需要用到排序稳定性的时候使用
满足稳定性,但是空间复杂度太高
排序的其他事项
目前还没有基于比较的排序能做到时间复杂度O(N*logN)以下
时间复杂度O(N*logN)情况下,空间复杂度在O(N)以下,还能做到稳定性的目前基于比较的排序也没有
即要想实现排序稳定性,空间复杂度O(N)已经是最小;要想速度快,空间复杂度低,就做不到稳定性
非常难的大坑【因为难实现,实现了也有替代方案,所以没啥意义】
归并排序内部缓存发可以实现空间复杂度O(1),很难,而且会丧失排序稳定性,不如用堆排
原地归并排序会让归并排序的时间复杂度由O(N*logN)变成O(N2);空间复杂度还是O(N),完全没有意义,不如其他几个
快排可以实现排序稳定,但是论文级难度,而且会让空间复杂度由O(logN)变成O(N),完全没意义,不如用归并
排序面试题大坑
要求数组中的奇数放在数组左边,偶数放数组的右边,还要求保存排序稳定性,空间复杂度O(1),时间复杂度O(N),可以直接怼面试官
思路:快排的值划分属于零一标准,和奇偶问题是同一种调整策略,等同与奇数放左边,偶数放右边,快排如果能做到<=划分值的放左边,>划分值的放右边且能维持排序稳定性,就能做到奇数放数组左边,偶数放数组右边,数字间保存相对次序,据我所知快排能做到保持排序稳定性,但是论文级别的难度,而且空间复杂度会变成O(N),快排做不到,我不知道如何实现
工程上对排序的改进
利用各个排序的独特优势实现综合排序
在大样本情况下用快排进行调度,划分为小范围【如数据量小于60】直接用插入排序【常数项小,样本量小瓶颈不明显】
java中Arrays.sort发现是基础类型就用快排,是自定义排序就用归并排序【一般系统中的排序都是很有很优秀的优化】
哈希表
哈希表有两种实现,HashSet和HashMap,底层都是哈希表,区别是
HashSet只使用key
HashMap使用key和value
哈希表的特性
哈希表执行增删改查无论多大数据量的增删改查时间复杂度都是常数级别的,只是认为该常数时间比较大【原理不懂】
基础类型数据【String、基本数据类型及其包装类】在哈希表中是值传递,会直接拷贝一份放入哈希表【很长的一个字符串是怎么放入哈希表的,主要是那个字符串常量池】;其他引用数据类型都是引用传递,一律都是8字节保存内存地址
哈希表的相关方法
HashSet HashMap add(k)【加一个key】put(k,v)【既是增加键值对也是更新value】remove(k)【移除一个key】remove(k)【会直接移除键值对】contains(k)【查询是否包含对应key】get(k)【通过key获取value,没有对应的key返回null】
有序表
有序表有TreeSet和TreeMap两种具体实现,底层很难,是红黑树、AVL树、sb树、跳表
TreeSet【也叫SortedSet】只使用key
TreeMap【也叫SortedMap】使用key和value
有序表的特性
有序表和哈希表的唯一区别是哈希表无序,有序表有序,有序表因为有序扩展了很多新功能
有序表的性能比哈希表差,所有的操作时间复杂度都是O(logN),放入有序表的东西不是基础类型在构建有序表的时候必须提供比较器,不提供就会报错
【左神示例】
xxxxxxxxxxpublic class Code01_HashAndTree {public static class Node {public int value;public Node next;public Node(int val) {value = val;}}//自定义有序表Node对象比较器public static class NodeComparator implements Comparator<Node> {public int compare(Node o1, Node o2) {return o1.value - o2.value;}}public static void main(String[] args) {Node nodeA = null;Node nodeB = null;Node nodeC = null;// treeSet的key是非基础类型->Node类型nodeA = new Node(5);nodeB = new Node(3);nodeC = new Node(7);TreeSet<Node> treeSet = new TreeSet<>();// 以下的代码会报错,因为没有提供Node类型的比较器try {treeSet.add(nodeA);treeSet.add(nodeB);treeSet.add(nodeC);} catch (Exception e) {System.out.println("错误信息:" + e.getMessage());}treeSet = new TreeSet<>(new NodeComparator());// 以下的代码没问题,因为提供了Node类型的比较器try {treeSet.add(nodeA);treeSet.add(nodeB);treeSet.add(nodeC);System.out.println("这次节点都加入了");} catch (Exception e) {System.out.println(e.getMessage());}}}
有序表的相关方法
TreeMap相关方法 备注 put(k,v)增加键值对或者更新value【有序不可重复】 containskey(k)查询有序表中有没有对应的key remove(k)通过key移除键值对 get(k)由key获得value firstKey(k)获取最小的key lastKey(k)获取最大的key floorKey(8)获取小于等于8并且离8最近的key ceilingKey(8)获取大于等于8且离8最近的key
链表
直接讨论链表面试题,注意:链表翻转设置一个函数如f(),传参一个头节点head1,f(head1)就能返回另一头的头节点head2
单向链表的翻转有两种方案:
一个是新建链表,用两个指针一边拆一边指向原链表下一个节点,一边在新链表头上上连接拆下来的节点,实现的关键是这四个循环变化过程:next = cur.next;cur.next = newQueue.next;newQueue.next = cur;cur = next;但是这种实现翻转破坏了原链表的顺序,原链表已经不存在了;当然你也可以翻转两次
不破坏链表的前提下逆序打印链表的printList()方法:实现原理,使用栈先入后出后入先出的特点对栈空间进行链表遍历压栈并弹栈,栈的push方法和add方法效果相同,java中栈的常用方法有push,add,size,pop
问题1:
给定两个有公共部分且节点value属性有序的链表头节点head1和head2,打印两个链表的公共部分,两个链表的长度之和为N,要求时间复杂度O(N),空间复杂度O(1)
思路:因为链表的value属性有序了,直接比较链表的指针指向节点的value属性,那个属性值小,那个指针就右移,右移后继续比较,重复上述步骤,有相同的同时取出,两指针同时右移,然后继续重复上述步骤
问题2:
笔试判断一个链表是否回文结构
回文结构:链表以节点文基本单位,节点的value属性在整个链表上是镜像关系,如
1->2->3->2->1、1->2->2->1笔试为了快,不要考虑空间复杂度,直接把链表节点元素按顺序遍历放入栈,从栈中依次取出元素元素,再次遍历链表逐个与栈中取出的节点元素的属性值作对比,完全一样就是回文结构,利用了栈的先进后出
更快可以找到链表的中点,只把链表的后一半从左到右依次放入栈中,再从栈中弹栈和链表的前半部分对比,完全相同即回文结构
面试只用几个有限空间判断一个链表是否回文结构
快慢指针遍历链表,慢指针指到链表中点后链表后半部分逆序
1->2->3->2->1变成1->2->3<-2<-1,同时3指向null,两边的头都用引用记下,同时向中间遍历并足部进行比对,指到走到null停下,如果遍历过程中对应节点的属性值都相同就是回文结构,注意返回true/false前需要将链表进行恢复【左神实现】
xxxxxxxxxx// need O(1) extra spacepublic static boolean isPalindrome3(Node head) {if (head == null || head.next == null) {return true;}Node n1 = head;Node n2 = head;//快指针while (n2.next != null && n2.next.next != null) { // find mid noden1 = n1.next; // n1 -> midn2 = n2.next.next; // n2 -> end}n2 = n1.next; // n2 -> right part first node,把快指针设置成右半边的头节点n1.next = null; // mid.next -> null,把中间节点指向nullNode n3 = null;//新建Node类型引用n3//右半部分链表翻转,?这里没考虑链表长度偶数的情况吧while (n2 != null) { // right part convert,当n2节点不为空n3 = n2.next; // n3 -> save next node,n3指向右半边第二个节点n2.next = n1; // next of right node convert,右半边第一个指向头节点n1 = n2; // n1 move//慢指针指向右半边第一个节点n2 = n3; // n2 move//快指针指向右半边第二个节点}//重复以上过程直到右半边链表完全翻转n3 = n1; // n3 -> save last node让n3指向右半边翻转后的头节点n2 = head;// n2 -> left first node让n2指向链表左半边头节点boolean res = true;//将链表默认设置成回文结构while (n1 != null && n2 != null) { // check palindrome//当两边头节点向中间遍历过程判断值属性是否不等,不等设置成非回文结构链表if (n1.value != n2.value) {res = false;break;}n1 = n1.next; // left to midn2 = n2.next; // right to mid}//链表恢复n1 = n3.next;//慢指针指向右半边倒数第二个节点n3.next = null;//将右半边头节点的next设置成nullwhile (n1 != null) { // recover list慢指针遍历右半边n2 = n1.next;//快指针指向倒数第三个节点n1.next = n3;//倒数第二个节点指向尾结点n3 = n1;//n3指向倒数第二个节点n1 = n2;//n1指向倒数第三个节点}//重复上述过程直到完全恢复链表,当中间节点的next会自动指向右半边节点return res;//返回是否回文节点}
快慢指针遍历找到链表中点:
快指针一次走两步,慢指针一次走一步,快指针走完的时候慢指针来到中点,这里需要对链表长度的奇偶进行慢指针的处理
代码实现:
直接快指针下一步会走到null就不走了,当前的慢指针就是中点位置【链表长度为偶数时为前半段最后一个判断回文结构都是从下一个点开始入栈】
xxxxxxxxxxwhile(n2.next !=null && n2.next.next!=null){n1=n1.next;n2=n2.next;}
将单向链表按值属性相对于指定值划分为左边小、中间等、右边大的形式
笔试实现,将单向链表的每个数都放入Node类型的数组【注意不是值数组】,在数组中用快排的值划分对指定值进行一次划分【partition】,输出数组节点展示即可
面试实现
用有限几个变量实现将
4->6->3->5->8->5->2链表中<5放左边、等于5的放中间、大于5的放右边,且保持排序稳定性【值划分无法保证排序稳定性,但是单链表可以】思路:设置六个空指针SH【<区的头】、ST【<区的尾】、EH【=区的头】、ET【=区的尾】、BH【>区的头】、BT【>区的尾】,由左到右依次判断每个节点的值属性,第一个取4,4比指定值小归于小于区,SH=4对应引用,ST=4对应引用【以后都用数字代替】;第二个取6,大于5,BH=6,BT=6;第三个取3,小于5,SH=4维持头指针不变,ST=3;第四个取5,等于5,EH=5,ET=5;...【核心就是从左到右筛选出小于区、等于区、大于区的数拼接在一起,各区域第一个为头指针,最后一个为尾指针】;划分完成,依次将小于区的尾指针指向等于区的头指针,等于区的尾指针指向大于区的头指针
首先解决链表长度为0的情况,将存在数据【即头指针不为null】的区域按小于区、等于区、大于区的顺序依次将存在区域头指针和尾指针存入数组,根据数组中存的下一个头指针不为null循环将尾指针的next指向下一个头指针,最后返回数组第一个头指针
【左神直接逻辑硬连:如果小于区有节点,小于区的尾结点连接等于区头节点,如果等于区有节点等于区尾结点为等于区尾结点;等于区没有节点小于区尾结点会自动连接null,等于区尾结点重新指向小于区的尾结点相当于小于区直接连接大于区;前面连接好的尾结点连接大于区头节点,大于区没有节点会自动连接null,核心还是让等于区尾结点连接大于区头节点,如果等于区有节点,等于区尾结点连接大于区头节点;如果等于区没有节点,等于区尾结点直接重新指向小于区尾结点;return语句自动处理了如果小于区和等于区都没有节点就返回大于区的头节点,意思是小于区有节点直接返回小于区的头,如果小于区没有头等于区有头就返回等于区的头,小于区没有头等于区没有头就返回大于区的头,都没有就返回null】
注意,规定了数组长度,即使数组元素没有被赋值也有默认值0
面试实现代码
【左神实现】
xxxxxxxxxxpublic static Node listPartition2(Node head, int pivot) {Node sH = null; // small headNode sT = null; // small tailNode eH = null; // equal headNode eT = null; // equal tailNode bH = null; // big headNode bT = null; // big tailNode next = null; // save next node// every node distributed to three lists//所有节点分成三个区域while (head != null) {//链表不为空next = head.next;//next指向第二个节点head.next = null;//将头节点从链表断开,这个节点实际是剩余链表断开的第一个if (head.value < pivot) {//若头节点归属小于区if (sH == null) {//是否第一个头节点sH = head;sT = head;} else {//不是第一个头节点sT.next = head;//上次小于区尾结点连接该新加入节点sT = head;//尾结点后移}} else if (head.value == pivot) {//等于区if (eH == null) {eH = head;eT = head;} else {eT.next = head;eT = head;}} else {//大于区if (bH == null) {bH = head;bT = head;} else {bT.next = head;bT = head;}}head = next;//把第二个节点从新作为头节点准备断节点进行区域划分}// small and equal reconnect//小于区和等于区重连if (sT != null) {//小于区有节点sT.next = eH;//小于区的尾结点连接等于区头节点,如果等于区有节点等于区尾结点为等于区尾结点;等于区没有节点会自动连接null,等于区尾结点重新指向小于区的尾结点eT = eT == null ? sT : eT;//等于区没有节点ET等于小于区尾结点,有节点ET等于小于区节点}// all reconnectif (eT != null) {//如果等于区有节点或者小于区有节点eT.next = bH;//等于区的尾结点连接大于区的头节点,大于区没有节点会前面的尾结点会自动连接null}return sH != null ? sH : eH != null ? eH : bH;//eH != null ? eH : bH等于区有节点返回等于区的头。没有返回大于区的头,如果大于区也没有头就返回null;小于区有节点返回小于区的头,如果小于区没有头等于区有头就返回等于区的头,等于区没有头就返回大于区的头,都没有就返回null}
问题5:复制含随机指针节点的链表
需求是拷贝一模一样的链表结构,包括随机指针的指向在链表上对应相同,但是两个链表对应节点的引用不同
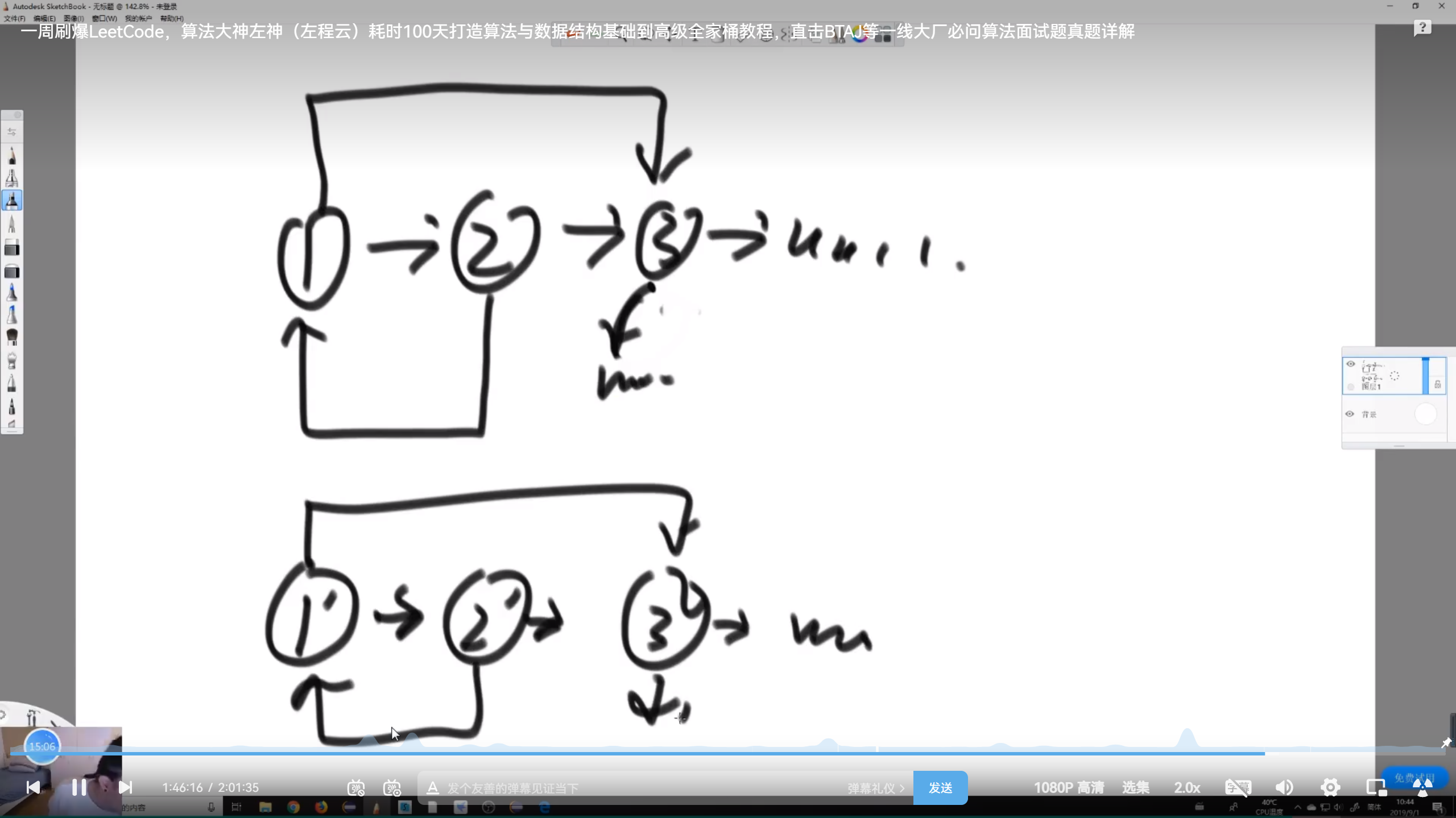
面试复制含随机指针节点的链表
思路:不要求空间复杂度O(1)的情况下直接用哈希表
遍历原链表,遍历过程中对每一个节点创建一个新节点,将原节点的value属性赋值给新节点的value属性,以原节点为key,新节点为value放入哈希表中;直至链表遍历结束
设置克隆节点的指针,遍历原链表,通过原节点1可以从哈希表获取对应新节点,通过原节点的next可以获得下一个节点2,通过2可以从哈希表获得2对应的新节点,将1新节点的next连接到2对应的新节点上;通过1的random可以找到3节点,通过3节点可以从哈希表获得3对应的新节点,将1新节点的random连接到3对应的新节点上;自此节点1对应的新节点的关系全部处理完;接着处理2节点知道遍历整个链表
最后返回新链表1对应新节点作为头指针
代码实现
【左神实现】
xxxxxxxxxxpublic static Node copyListWithRand1(Node head) {HashMap<Node, Node> map = new HashMap<Node, Node>();Node cur = head;while (cur != null) {map.put(cur, new Node(cur.value));cur = cur.next;}cur = head;while (cur != null) {map.get(cur).next = map.get(cur.next);map.get(cur).rand = map.get(cur.rand);cur = cur.next;}return map.get(head);}
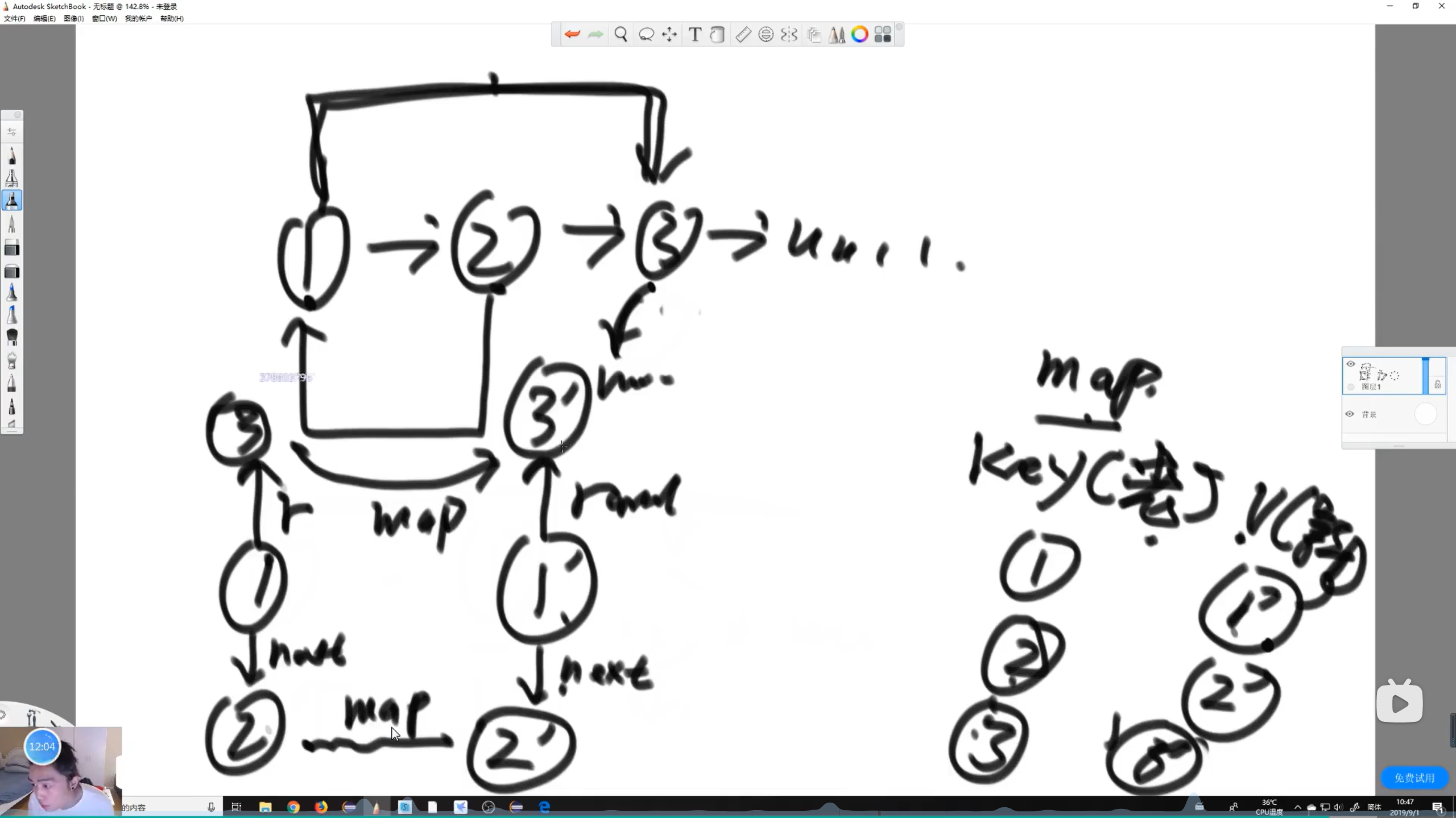
不使用哈希表在有限空间复杂度的情况下复制含随机指针节点的链表
核心是利用链表成对对应把哈希表省略了
下随机指针节点链表的复制.png)
思路
遍历原链表,根据每个节点创建对应新节点并设置相同的value属性值,然后将新节点插入链表原节点的后面,保证成双成对
由1的next可以找到1对应新节点,由1的random可以找到3,由3的next可以找到对应3的新节点,将1的新节点的random连接到3对应的新节点;注意判断如果random等于null,那么对应新节点的random也为null;
然后通过next属性按奇偶把原链表和新链表分离出来
最后返回新链表的头
代码实现
【左神实现】
xxxxxxxxxxpublic static Node copyListWithRand2(Node head) {if (head == null) {return null;}Node cur = head;Node next = null;// copy node and link to every node,创建原链表对应节点的新节点并将其插入到原节点后面while (cur != null) {next = cur.next;cur.next = new Node(cur.value);cur.next.next = next;cur = next;}cur = head;Node curCopy = null;// set copy node rand,处理链表的rand属性while (cur != null) {next = cur.next.next;curCopy = cur.next;curCopy.rand = cur.rand != null ? cur.rand.next : null;cur = next;}Node res = head.next;cur = head;// split,使用cur和curCopy、next集合next属性分割链表为两个链表while (cur != null) {next = cur.next.next;curCopy = cur.next;cur.next = next;curCopy.next = next != null ? next.next : null;cur = next;}return res;}
两单链表相交问题
以下的所有方法的时间复杂度都是O(N)级别,空间复杂度都为O(1),都没有使用任何大的数据结构
题目:给定两个可能有环也可能无环的单链表,头节点分别为head1,head2;实现一个函数,如果两链表相交,返回相交的第一个节点,不相交则返回null;【相交即有共用节点,注意相交节点的内存地址必然相同,相交节点之后的所有节点也必然共用】
思路:要先解决判断链表有环无环的问题,这样才好对链表相交问题进行分类讨论
步骤一:分别求两链表的第一个入环节点loop1和loop2
步骤二:如果loop1和loop2均为null,意味着两单链表都无环,两链表相交只可能相交之后的部分都是公有的,即最后一个节点是公共的,则两链表相交;
遍历第一个链表,记录末尾节点end1,记录长度假如length1=100;遍历第二个链表,记录末尾节点end2,记录长度假如length2=80;如果
end1=end2,则两链表相交;要找相交的第一个节点,先让长链表先走length1-length2,然后两链表一起每次走一步,两必然在第一个相交点处相遇【因为第一个相交节点后的所有节点必然共用】【左神实现】
xxxxxxxxxxpublic static Node noLoop(Node head1, Node head2) {if (head1 == null || head2 == null) {//两链表有一个长度为0,就返回nullreturn null;}Node cur1 = head1;//准备遍历两链表Node cur2 = head2;int n = 0;//准备记录两链表长度while (cur1.next != null) {//当链表下一个节点不为null,就一直遍历n++;//步数加1,这里的n指的是指针走的步数,走到最后一个节点,走了节点数-1步cur1 = cur1.next;}while (cur2.next != null) {n--;//当链表下一个节点不为null、在链表一走的步数的基础上减去一步,相当于链表1的步数-链表2的步数,即两链表相差的步数cur2 = cur2.next;}if (cur1 != cur2) {//如果尾节点不是共用节点,直接返回nullreturn null;}cur1 = n > 0 ? head1 : head2;//如果n大于0,则链表1长,否则链表2长,哪个长cur1作为谁的头指针cur2 = cur1 == head1 ? head2 : head1;//cur2为另一条链表的头指针n = Math.abs(n);//多出来的步数取绝对值while (n != 0) {//长链表先走n步n--;cur1 = cur1.next;}while (cur1 != cur2) {//长短链表一起走,直到两链表节点公有cur1 = cur1.next;cur2 = cur2.next;}return cur1;//返回相交节点}
步骤三:如果loop1、loop2有一个为空,一个不为空
两链表不可能相交,因为相交的最后一个节点必然共有
【左神实现】
xxxxxxxxxxpublic static Node getIntersectNode(Node head1, Node head2) {if (head1 == null || head2 == null) {//只有一个loop为null就返回nullreturn null;}Node loop1 = getLoopNode(head1);Node loop2 = getLoopNode(head2);if (loop1 == null && loop2 == null) {//两链表都不是环形链表的情况return noLoop(head1, head2);}if (loop1 != null && loop2 != null) {//两链表都是有环的情况return bothLoop(head1, loop1, head2, loop2);}return null;}
步骤四:如果loop1,loop2都不为空,即都有环,一共有三种情况

loop1!=loop2对应于情况1和情况3,让loop1继续往下走,再再次遇到loop1之前能遇到loop2就是情况3,遇不到就是情况1;情况1没有相交节点,直接返回null;
情况3有相交节点,返回loop1和loop2都可以,都叫第一个相交节点
loop1=loop2对应于情况2,以loop1和loop2作为链表终点,让长链表先走先走X步然后两链表一起走,直到第一次遇到公共节点,即相交节点
【左神实现】
xxxxxxxxxxpublic static Node bothLoop(Node head1, Node loop1, Node head2, Node loop2) {Node cur1 = null;Node cur2 = null;if (loop1 == loop2) {//如果两入环节点相等cur1 = head1;//准备遍历两个链表得到长链表,并找出第一个相交的节点cur2 = head2;int n = 0;while (cur1 != loop1) {//遍历两链表并记录长链表多出来的步数,遍历到loop1即可n++;cur1 = cur1.next;}while (cur2 != loop2) {n--;cur2 = cur2.next;}cur1 = n > 0 ? head1 : head2;//选取长链表cur2 = cur1 == head1 ? head2 : head1;//选取短链表n = Math.abs(n);while (n != 0) {//长链表先走多出来的步子n--;cur1 = cur1.next;}while (cur1 != cur2) {//两链表一起走找相交链表cur1 = cur1.next;cur2 = cur2.next;}return cur1;} else {//情况1和情况3cur1 = loop1.next;//从loop1开始遍历while (cur1 != loop1) {//当再次到大loop1以前如果遇到loop2就返回loop1if (cur1 == loop2) {return loop1;}cur1 = cur1.next;//遍历公有环}return null;//没有遇到loop2就返回null}}
判断链表有环无环,有环返回第一个环节点
笔试直接用Set集合
遍历链表,对第一个节点判断是否在set集合中,不在将该节点放入set集合中,再遍历下一个节点,判断是否在set集合中,不在将该节点放入set集合中,以此类推遍历所有的节点
如果直接走到空节点,说明链表肯定没环【因为有环意味着入环节点的下一个节点必然在环上,否则入环节点必须有两个next指针,即一个链表有环,必然会掉环里出不来】;如果来到C节点,第一次发现C节点有重复的,C节点就是入环节节点,返回C节点即可
面试不使用额外数据结构【快慢指针】
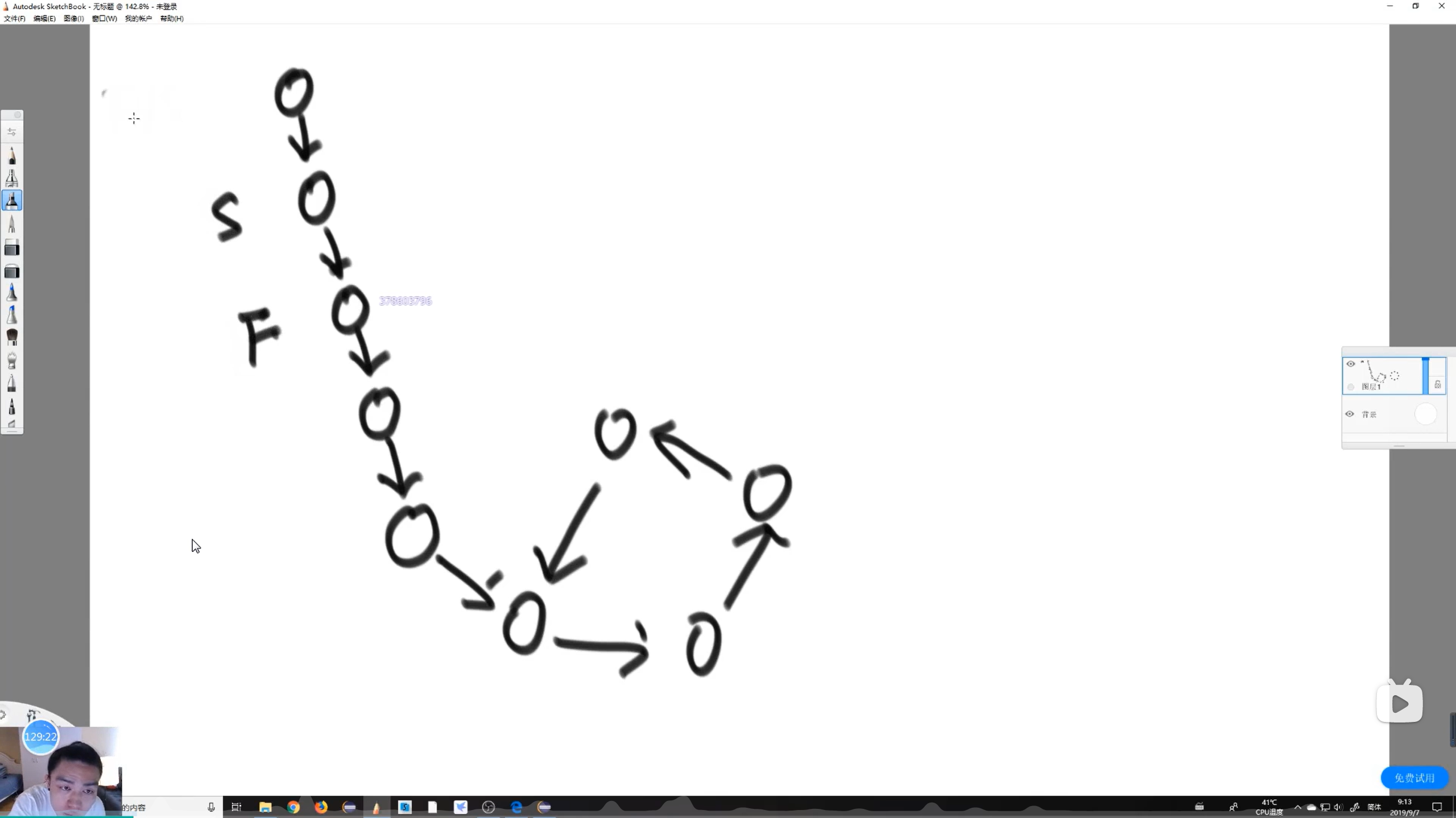
快指针和慢指针都从第一个节点出发,快指针一次走两步,慢指针一次走一步;快指针如果能走到null,链表肯定没有环
如果链表有环,快慢指针一定能在环上相遇,而且快慢指针转的全书一定不会大于两圈以上【因为快指针比慢指针快一倍,不会允许慢指针转完一圈还追不上慢指针,时间复杂度不会变得很大】
快慢指针相遇后,快指针回到链表头,慢指针停留在相遇处,接下来快慢指针都一次走一步,两指针一定会在快指针第一次通过入环节点出相遇【因为由第一次相遇可推得
x=ny-k,x为非环节点数,也即快指针一步一步走到入环节点的步数;n是快慢指针第一次相遇前快指针的绕环圈数;y是环节点数;k是快慢指针第一次相交时慢指针在环上走过的节点数;意思是当快指针一步一步走到入环节点时,慢指针对应走ny-k步,即慢指针也刚好停在入环节点处】代码实现
【左神实现】
xxxxxxxxxxpublic static Node getLoopNode(Node head) {if (head == null || head.next == null || head.next.next == null) {//如果链表节点数小于3,直接返回null,因为无法构成环return null;}Node n1 = head.next; // n1 -> slow,n1为慢指针Node n2 = head.next.next; // n2 -> fast,n2为快指针while (n1 != n2) {//一直循环直到快慢指针相遇if (n2.next == null || n2.next.next == null) {//如果链表没有环结构直接返回nullreturn null;}n2 = n2.next.next;//快指针一次走两步n1 = n1.next;//慢指针一次走一步}n2 = head; // n2 -> walk again from head,两指针相遇快指针回到链表头节点while (n1 != n2) {//两指针都一次走一步,直到相遇n1 = n1.next;n2 = n2.next;}return n1;//返回相遇的节点即入环节点}
二叉树
二叉树
二叉树的节点Node有三个属性,value属性用来保存值,Node left属性指向左孩子节点,Node right属性指向右孩子节点,所有节点不形成环就能串出二叉树【左孩子和右孩子都为null的节点叫叶节点,最顶上的节点叫做根节点,也叫作头节点】
二叉树的递归遍历
二叉树最常见的遍历方式就是递归
递归遍历二叉树

递归序
在递归序的基础上可以发展出先序、中序、后序遍历;注意先、中、后序遍历都是每个值只打印一次,只是打印的时机不同
【左神实现】
xxxxxxxxxxpublic static void ergodic(Node head){if(head==null){return;}System.out.println(head.value);//写到这里叶节点的子节点null不会打印值也不会空指针异常ergodic(head.left);System.out.println(head.value);ergodic(head.right);System.out.println(head.value);}递归序
1、2、4、4、4、2、5、5、5、2、1、3、6、6、6、3、7、7、7、3、1,每个节点都会回回到3次,包括1
先序遍历【头左右,以头所在位置为标准,头在第一个,第一次到栈打印】
含义:对于所有的节点,先打印头节点,在打印左子树上的所有节点,再打印右子树上的所有节点
由递归序加工而成,每次第一次到某个节点就打印节点属性值,2、3次到什么也不干【准确的说是第一次到对应的栈内】
1、2、4、5、3、6、7、代码实现:
xxxxxxxxxxpublic static void preOrderRecur(Node head) {if (head == null) {return;}System.out.print(head.value + " ");//第一次到对应栈内打印preOrderRecur(head.left);preOrderRecur(head.right);}
中序遍历【左头右,头在第二个,第二次到栈打印】
对任意一个节点,先打印左子树上的所有节点,在打印头节点,再打印右子树上的所有节点
第二次到栈打印节点,1、3次到栈啥也不做
4、2、5、1、6、3、7代码实现
xxxxxxxxxxpublic static void inOrderRecur(Node head) {if (head == null) {return;}inOrderRecur(head.left);System.out.print(head.value + " ");inOrderRecur(head.right);}
后序遍历【左右头,头在第三个,第三次到栈打印】
对任意一个节点,先打印左子树上的所有节点,再打印右子树上的节点,最后打印头节点
第三次到栈打印节点,1、2次到栈啥也不做
4、5、2、6、7、3、1代码实现
xxxxxxxxxxpublic static void posOrderRecur(Node head) {if (head == null) {return;}posOrderRecur(head.left);posOrderRecur(head.right);System.out.print(head.value + " ");}
二叉树的非递归遍历【相当于不让系统自动压栈,自己来进行压栈】
非递归的方式面试经常写
先序遍历
核心是弹栈头的时候,将左右子节点按右左的顺序同时入栈、弹栈自然就是左右【开始压入根节点,此后重复弹栈头节点的时候按右左的顺序压栈子节点】,一个栈反转一次,为右左
步骤
第一步:准备一个栈,先把头节点压入栈中
第二步:从栈中弹出一个节点设为cur,
第三步:处理cur比如打印
第四步:如果cur有有子节点,先把右孩子压入栈中,再把左孩子压入栈中,没有子节点什么也不做,直接进入第二步继续弹栈
周而复始2-4步,直到栈空间无法弹栈
代码实现
【左神实现】
记住栈是否空用isEmpty判断、弹栈是pop、压栈是push;栈在java中实现类是Stack
xxxxxxxxxxpublic static void preOrderUnRecur(Node head) {System.out.print("pre-order: ");if (head != null) {Stack<Node> stack = new Stack<Node>();stack.add(head);while (!stack.isEmpty()) {//判断条件是栈不为空,因为循环第一件事就是弹栈head = stack.pop();//弹栈System.out.print(head.value + " ");//打印弹栈节点if (head.right != null) {//有右孩子压栈右孩子stack.push(head.right);}if (head.left != null) {stack.push(head.left);//有左孩子压栈左孩子}}}System.out.println();}
后序遍历
除了基本的栈,还准备一个收集栈,开始压入根节点,弹栈头节点放入收集栈,同时按左右的顺序压栈子节点,最后单独一次性弹栈收集栈的节点并答应节点信息【收集栈会再次反转右左节点,所以入栈是左右;核心栈弹栈右左,收集栈弹栈左右】,两个栈反转两次,为左右
步骤:
第一步:准备两个栈,栈和收集栈,先向栈中压入根节点
第二步:栈中弹出一个节点cur
第三步:cur压入收集栈中
第四步:如果cur有子节点,先压栈左子节点,在压栈右子节点,没有子节点什么也不做,直接进入第二步继续弹栈
周而复始2-4步,直到栈空间无法弹栈
第五步:弹栈收集栈并打印收集栈中的节点信息
代码实现:
【左神实现】
xxxxxxxxxxpublic static void posOrderUnRecur1(Node head) {System.out.print("pos-order: ");if (head != null) {Stack<Node> s1 = new Stack<Node>();//栈Stack<Node> s2 = new Stack<Node>();//收集栈s1.push(head);//栈中压入根节点while (!s1.isEmpty()) {//栈中为空时结束循环head = s1.pop();//栈弹栈curs2.push(head);//收集栈压栈curif (head.left != null) {//有左孩子压栈左孩子s1.push(head.left);}if (head.right != null) {//有右孩子压栈右孩子s1.push(head.right);}}while (!s2.isEmpty()) {//把收集栈弹空并打印节点信息System.out.print(s2.pop().value + " ");}}System.out.println();}
中序遍历
原理:二叉树可以被左边界分解掉,压栈是先头后所有左边界,弹栈就是先左边界后头,一个节点弹出时再让其右树周而复始【压入头和左边界,弹栈节点是再按这个方法分解所有右子树】,相当于整棵树按左边界分解掉了,只是右数的左边界后分解
步骤:
第一步:对整颗二叉树,先把树的左边界包括根节点全部按上到下压入栈
第二步:弹栈一个节点cur
第三步:打印节点cur信息
第四步:若cur有右子树,让右子树的所有左边界入栈,否则继续第二步弹栈
周而复始2-4步,直到栈空间无法弹栈
代码实现
【左神实现】
这一步左神把整颗二叉树的左边界和右子树的左边界压栈统一在了一起
xxxxxxxxxxpublic static void inOrderUnRecur(Node head) {System.out.print("in-order: ");if (head != null) {//二叉树有节点Stack<Node> stack = new Stack<Node>();while (!stack.isEmpty() || head != null) {//当栈不为空或者根节点不为空,这个head主要判断整棵树或者右子树有节点将左边界全部压入栈的if (head != null) {//根节点不为null且左孩子不为空,对整棵树或者右子树左边界没压栈完成都会一直在这个循环压栈stack.push(head);//压栈根节点head = head.left;//并把head移至左孩子} else {head = stack.pop();//左边界压栈完成,开始弹栈System.out.print(head.value + " ");//打印弹出节点信息head = head.right;//head赋值右子树}}}System.out.println();}
直观打印二叉树
不需要掌握,这个是左神为了方便二叉树做题提供的形象化二叉树的函数
代码实现
【左神实现】
xxxxxxxxxxpublic class Code02_PrintBinaryTree {public static class Node {public int value;public Node left;public Node right;public Node(int data) {this.value = data;}}public static void printTree(Node head) {//这个是打印二叉树的方法System.out.println("Binary Tree:");printInOrder(head, 0, "H", 17);System.out.println();}public static void printInOrder(Node head, int height, String to, int len) {if (head == null) {return;}printInOrder(head.right, height + 1, "v", len);String val = to + head.value + to;int lenM = val.length();int lenL = (len - lenM) / 2;int lenR = len - lenM - lenL;val = getSpace(lenL) + val + getSpace(lenR);System.out.println(getSpace(height * len) + val);printInOrder(head.left, height + 1, "^", len);}public static String getSpace(int num) {String space = " ";StringBuffer buf = new StringBuffer("");for (int i = 0; i < num; i++) {buf.append(space);}return buf.toString();}public static void main(String[] args) {//这个是打印二叉树的测试Node head = new Node(1);head.left = new Node(-222222222);head.right = new Node(3);head.left.left = new Node(Integer.MIN_VALUE);head.right.left = new Node(55555555);head.right.right = new Node(66);head.left.left.right = new Node(777);printTree(head);head = new Node(1);head.left = new Node(2);head.right = new Node(3);head.left.left = new Node(4);head.right.left = new Node(5);head.right.right = new Node(6);head.left.left.right = new Node(7);printTree(head);head = new Node(1);head.left = new Node(1);head.right = new Node(1);head.left.left = new Node(1);head.right.left = new Node(1);head.right.right = new Node(1);head.left.left.right = new Node(1);printTree(head);}}
二叉树的宽度优先遍历
注意:二叉树的深度优先遍历就是先序遍历
二叉树宽度优先遍历
步骤:
第一步:准备一个队列,将头节点加入队列
第二步:从队列中弹出一个节点
第三步:如果弹出当前节点有左孩子,将左孩子放入队列;如果当前节点有右孩子,将有孩子放入队列,一定要遵从先左后右
代码实现
【左神实现】
xxxxxxxxxxpublic static void breadthFirstSearch(Node head){if (head==null){//二叉树没有节点直接返回return;}Queue<Node> queue=new LinkedList<>();queue.add(head);while(!queue.isEmpty()){Node cur = queue.poll();//队列弹出一个System.out.println(cur.value);//打印出队列的节点属性值if (cur.left!=null){//有右孩子右孩子入队列queue.add(cur.left);}if (cur.right!=null){queue.add(cur.right);}}}
题目1:求一棵二叉树的最大宽度【宽度就是二叉树某一行一行有几个节点】
笔试解答
核心是一个节点加入队列的时候要保存其行数信息,用HashMap来保存这个行数信息,出队列时获取对应层数信息与当前层数信息对比【注意当前层数curLevel的初始值是1】,如果获取的层数信息更大,说明当前层节点已经出队列完了,可以结算当前层进入已经弹出一个节点的下一层了,此时curLevelNodes先更新max,然后重新赋值1,表示当前层已经出了一个节点,curLevel自加1表示当前层已经来到下一层;如果出队列的节点还是当前层的,当前层数节点数curLevelNodes就自加1
第一步:准备一个名为levelMap的HashMap,准备一个队列,准备四个变量
curLevel:当前层数,初始值为1,curLevelNodes:当前层数节点数,初始值为0,max:统计那一层的节点数是最多的,curNodeLevel:保存通过弹出节点从hashMap中拿到的弹出节点层数第二步:将根结点和层数信息【head,1】添加到levelMap中,将根结点放入队列中
第三步:从队列中弹出一个节点,从levelMap中根据节点拿到层数信息赋值给curNodeLevel
第四步:如果从HashMap中拿到的弹出节点的层数等于当前层数curLevel,则当前层数的节点数curLevelNodes自加1;如果curNodeLevel不等于curLevel,结算最大节点数curLevelNodes是否节点数最多的那一层,并把节点数赋值给max,当前层数curLevel自加1,当前层数节点数curLevelNodes重新赋值1
第五步:如果弹出节点有左孩子,将左孩子作为key,从hashMap拿出弹出节点的层数加1即作为value【左孩子的层数】存入hashMap;同理有右孩子,将右孩子和层数信息存入HashMap
周而复始3-5步,直到队列中没有节点
第六步:因为循环判断是队列还有没有节点,当最后一个节点出完,最后一层没有下一层来更新最后一层的节点数信息,需要再单独统计更新一次max
代码实现
【左神实现】
xxxxxxxxxxpublic static int getMaxWidth(Node head) {if (head == null) {//二叉树没有节点直接返回0return 0;}int maxWidth = 0;//定义最大某一层节点数int curWidth = 0;//定义当前层节点数int curLevel = 0;//定义当前层数初始值为0,没问题,因为头节点出队列就更新了curLevel=1,此后都是正常的HashMap<Node, Integer> levelMap = new HashMap<>();levelMap.put(head, 1);//存入根结点的层数信息LinkedList<Node> queue = new LinkedList<>();//ArrayList就是队列queue.add(head);//根结点入队列Node node = null;//用node来表示出队列的节点Node left = null;Node right = null;while (!queue.isEmpty()) {//当队列有节点就一直循环node = queue.poll();//弹出一个节点nodeleft = node.left;right = node.right;if (left != null) {//如果弹出节点的左节点不为空,获取子节点层数信息并存入HashMap,并将子节点加入队列levelMap.put(left, levelMap.get(node) + 1);queue.add(left);}if (right != null) {//如果弹出节点的右节点不为空,获取子节点层数信息并存入HashMap,并将子节点加入队列levelMap.put(right, levelMap.get(node) + 1);queue.add(right);}if (levelMap.get(node) > curLevel) {//如果出队列节点层数大于当前队列curWidth = 0;//当前层的节点数重新赋值0,感觉这里有问题,应该赋值1吧?表示已经出了一个了curLevel = levelMap.get(node);//通过弹出节点获取当前层数信息,相当于自加1} else {curWidth++;//如果出队列节点层数还是当前层数,当前层数节点数自加1}maxWidth = Math.max(maxWidth, curWidth);//这里也不好吧,没有必要每次循环都结算,直接在换层时结算即可,好处是最后一次页结算了}return maxWidth;}面试解答
不使用哈希表求二叉树的最大宽度【但是还是需要使用队列】,核心是上一行节点出队列记录节点数并让子节点进队列,用nexEnd记录下一层最后一个节点,当上一层出队列到最后一个节点时,结算当前行的节点数是否二叉树最大宽度,将下一行最后一个节点赋值给当前行最后一个节点继续出队列【没有给code,遇到相关的题再完善】
步骤
第一步:准备变量
curEnd:现在弹出节点所在层中的最后一个节点,初始值为head、nextEnd:当前弹出节点所在层中下一层的最后一个节点,初始值为null,curLevel:当前层,curLevelNodes:当前行最大节点数,max:二叉树最大宽度第二步:让根节点入队列
第二步:队列弹出一个节点,检查该节点有无左孩子,有左孩子,左孩子进队列,此时nextEnd设置成当前进队列的节点;再检查弹出节点有无右孩子,有就进队列,nextEnd设置成当前进队列的节点;curLevelNodes自加1
检查弹出节点是否curEnd,如果是curEnd,结算max,把nextEnd拷贝到curEnd,让curLevel自加1
周而复始执行3-4步直到队列没有节点
堆
堆结构
完全二叉树:二叉树每层都是满的,不满的一层只能是最后一层,且该层也是从左到右变满的【比如跳过某节点下的左节点,直接上右节点,就不是完全二叉树】
数组从0开始的一段可对应成完全二叉树【数组下标依次从左到右,如果某个节点对应的数组下标越界了,就认为该节点不存在了】
完全二叉树对应数组是节点下标和子节点下标存在统一对应关系的二叉树,性质是知道一个节点的数组下标,其对应子节点和父节点都可以通过下标从数组中方便的找到
注意只有一个头节点也可以称为一棵树

一个节点对应数组的下标为
i,在完全二叉树中其父节点对应数组的下标为(i-1)/2,左子节点下标2*i+1,右子节点下标2*i+2
堆是特殊的完全二叉树
大根堆:每个节点为头的子树,子树上的最大值就是该头节点
弄成大根堆的好处是根节点的值即数组下标为0的节点的值就是大根堆中的最大值,简言之,大根堆中的最大值总是可以直接通过下标0从数组中获取
小根堆:每个节点为头的子树,子树上的最小值就是该头节点
将数组从下标0开始的一段搞成一个大根堆
数组中选一个值放入一个堆,heapsize【初始值为0】自增1
通过向堆中插入的值的下标如2找到其父节点的下标0,如果该插入值比父节点的值大,则插入值在数组中与父节点位置互换【数组中换,堆中位置自然跟着换】,重复上述过程直到该插入值小于等于父节点的值,当小于等于父节点时就停在对应的节点
【这个不停地向上比较,节点互换的过程称为heapInsert过程】
找到堆中的最大值并将最大值从堆中去掉的操作
返回头节点即数组下标0,将大根堆最后一个元素如4复制一份给下标0,将heapsize自减1,此时根节点的4和两个子节点中的最大值比较,如果根节点更小就与最大子节点互换位置;换下去以后继续和子节点最大值比较互换位置知道其作为父节点比子节点都大或者没有子节点时停止
【从一个节点向下调整的过程叫heapify,这个过程通过heapsize来控制对的大小,通过heapsize发现数组越界就认为下移结束了,即左孩子对应下标大于等于heapsize意味着没有孩节点了,如果有孩子节点,判断是否有右孩子节点,右孩子节点的值是否大于左孩子节点的值,返回两孩子节点中值较大节点的下标给变量largest,然后与父节点比较,将父节点和孩节点中的最大值的下标给largest,如果largest为父节点下标,说明下移到位,跳出下移循环,否则largest对应子节点和父节点位置互换,指向头节点的指针移至largest对应下标的节点,获取新的左子节点继续循环上述下移过程】
用户将堆中一个数据的值修改后仍保持是堆的操作
判断对应数据变大还是变小
先判断能不能heapInsert,因为相等或者小于父节点都不会执行heapInsert,再看是否需要heapify
数据变大:向上一次heapInsert调整
数据变小:向下一次heapify调整
加入一个数字时调整的时间复杂度
完全二叉树的高度height和heapsize的关系为height=logheapsize,一次heapInsert最多只会调整logheapsize-1个位置,因此时间复杂度为O(logN)
移除一个最大值向下调整的heapify过程最差还是(logN)-1个调整,所以向下调整的时间复杂度还是O(logN)
雪花算法
唯一全局ID生成
集群高并发情况下保证分布式唯一全局id的生成
分布式全局唯一id的业务需求
UUID、数据库自增主键【auto_increment】
分布式集群存在时钟和全局不重复的问题
复杂分布式系统中,需要对大量数据和消息进行唯一标识【如支付、酒店、电影票等数据,订单、骑手、优惠券等都需要唯一ID作为标识】,因此需要一种能够生成全局唯一ID的方法是很有必要的【全局唯一ID保证服务器扩容的情况下不会发生ID重复的情况】
ID生成规则的硬性要求
全局唯一【系统中不能出现重复的ID号】
趋势递增【mysql的InnoDB引擎使用的是聚集索引,多数RDBMS使用Btree的数据结构来存储索引数据,在主键的选择上应该尽量使用有序的主键来保证写入性能,InnoDB的特性就是将内容存储在主键索引树上的叶子结点,且从左到右递增,一般生成的ID单调递增会提高数据库的索引查询性能,如果无序会在叶子节点产生空位留白】
单调递增【净量保证下ID的生成随时间递增,以满足如事务版本号、IM增量消息、排序等特殊要求】
信息安全【需要ID净量无规则不规则,因为如果ID是连续的,恶意扒取就会变得相对容易,直接按顺序使用ID拼成指定URL即可,订单号就更危险,可以直接获取某天的单量】
含时间戳【可以快速了解分布式ID的生成时间,利于故障排查】
ID生成系统的可用性要求【假如算法部署在mysql服务器上,假设服务器宕机,所有业务就无法生成唯一标识号,因此生成唯一ID的算法部署服务器对硬件也有硬性要求】
高可用【要保证对获取分布式ID的请求,99.999%的情况下都要能成功创建唯一的分布式ID】
低延迟【发送获取分布式ID的请求,服务器要能急速处理】
高QPS【高并发访问的情况下要能处理所有的获取分布式ID的请求】
分布式ID生成的一般方案
snowflake【雪花算法】
Teitter的分布式自增ID算法snowflake,Twitter将存储系统从mysql迁移到Cassandra【由Facebook开发的一套开源分布式NoSQL数据库系统,可以看做Facebook版的redis】,因为Cassandra没有顺序ID生成机制,所以开发了一套全局唯一ID生成服务
雪花算法每秒能够产生26万个自增可排序的ID,在分布式系统内不会发生ID碰撞【由datacenter(数据中心)和workerId(机器码)作区分】且效率极高
雪花算法生成的ID能够按时间顺序有序生成
雪花算法生成的id是一个64bit的整数,为LONG型【LONG类型转换成字符串后长度最多19位字符串,而UUID转换成字符串不含连接符是32位】
满足无规则条件,防止别人爬取某台的交易量
雪花算法的核心部分
第一个bit是符号位,永远为0,因为1表示负数,0表示正数,生成的id一般都是用整数,最高位固定位0
1bit的时间戳可以表示69.73年,最小时间单位是1ms,就是使用雪花算法的系统可以使用69.73年保证不重复【这个竟然不能初始化时间1970年到2039年】,表示从0-2^{41}
xxxxxxxxxxpublic class TestUUID {public static void main(String[] args) {System.out.println(UUID.randomUUID());//ae9eaeb2-b467-4303-aa4c-df9769910235StringBuilder stringBuilder=new StringBuilder();for (int i = 0; i < 41; i++) {stringBuilder.append('1');}System.out.println(stringBuilder);//11111111111111111111111111111111111111111,这是雪花算法的时间戳部分System.out.println(stringBuilder.length());//41String endTimeString = stringBuilder.toString();//将二进制字符串转换成Long类型的十进制整数long endTimeLong = Long.parseLong(endTimeString, 2);System.out.println(endTimeLong);//2199023255551String endTimeDate = new SimpleDateFormat("yyyy-MM-dd").format(endTimeLong);System.out.println(endTimeDate);//2039-09-07}}10bit位表示工作进程位,分成前五个和后五个,前五个bit表示数据中心,后五个表示机器码,表示某个机房的哪一台机器,整体表示可以部署在2^{10}=1024个机器节点上,即最多可以有32个机房,每个机房可以有最多32台机器
12bit位序列号位,用来记录一个毫秒内产生的不同id,12bit可以表示0-(2^{12}-1)即0-4095个数字,表示同一个机器同一时间截【毫秒】内可以生成4096个ID序列号,理论上同一台机器可以生成409w6000个id
一共64位,所以雪花算法生成的id就是直接使用Long类型来存储

雪花算法的源码
官方网址:
github.com/twitter-archive/snowflake使用的是scale语法写的,网上活雷锋参考改出了一套java版本的
雪花算法java版源码
xxxxxxxxxx/*** @author Earl* @version 1.0.0* @描述 雪花算法生成唯一ID的原理* @创建日期 2023/12/04* @since 1.0.0*/public class SnowflakeIdWorker {/*** 工作机器Id(0-31)*/private long workerId;/***数据中心Id(0-31)*/private long datacenterId;/***毫秒内序列(0-4095)*/private long sequence = 0L;/***上次生成ID的时间戳,还没有生成初始值为-1*/private long lastTimestamp = -1L;/***系统开始时间截*/private final long twepoch=1420041600000L;/***机器id所占的位数,这个不是固定的,可以根据实际情况自定义*/private final long workerIdBits=5L;/***数据中心标识id占据位数*/private final long datacenterIdBits=5L;/***支持的最大机器ID,结果是31(由位移算法快速计算出表示机器码的几位二进制能表示的最大十进制数)*/private final long maxWorkerId=-1L^(-1L<<workerIdBits);/***支持的最大数据中心标识id,结果是31*/private final long maxDatacenterId=-1L^(-1L<<datacenterIdBits);/***序列在id中占的位数*/private final long sequenceBits=12L;/***机器ID向左移12位,准备合并唯一id,定好机器ID需要左移的次数*/private final long workerIdShift=sequenceBits;/***数据标识id向左移17位*/private final long datacenterIdShift=sequenceBits+workerIdBits;/***时间截需要左移的位数(5+5+12)*/private final long timestampLeftShift=sequenceBits+workerIdBits+datacenterIdBits;/***生成序列的掩码,此处为4095(0b1111111111=0xfff=4095)*/private final long sequenceMask=-1L^(-1L<<sequenceBits);//==================================Constructors=========================================/*** @param workerId 机器ID(0-31)* @param datacenterId 数据中心ID(0-31)* @return* @描述* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public SnowflakeIdWorker(long workerId,long datacenterId) throws IllegalAccessException {if (workerId>maxWorkerId || workerId <0) {//String.format类似于C语言的将后面的变量赋值给输出字符串中的占位符throw new IllegalAccessException(String.format("worker Id can't be greater than %d or less than 0",maxWorkerId));}if (datacenterId>maxDatacenterId || datacenterId<0){throw new IllegalAccessException(String.format("datacenter Id can't be greater than %d or less than 0"));}this.workerId=workerId;this.datacenterId=datacenterId;}//==================================Methods=========================================/*** @return long* @描述 该方法是线程安全的,这个就是获取唯一ID的方法* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public synchronized long nextId(){long timestamp=timeGen();//如果当前时间小于上一次ID生成的时间截,说明系统时钟回退过,此时应该抛出异常if(timestamp < lastTimestamp){throw new RuntimeException(String.format("CLock moved backwards. Refusing to generate id for %d milliseconds",lastTimestamp-timestamp));}//如果当前ID和上一个ID是同一时间截内生成的,则进行毫秒内序列处理if(lastTimestamp == timestamp){sequence = (sequence + 1) & sequenceMask;//毫秒内序列溢出if(sequence == 0){//阻塞到下一个毫秒,获得新的时间戳timestamp = tilNextMillis(lastTimestamp);}}//时间戳改变,毫秒内序列重置else{sequence=0L;}//上次生成ID的时间截lastTimestamp = timestamp;//位移并通过或运算拼到一起组成64位的IDreturn ((timestamp - twepoch) << timestampLeftShift) | (datacenterId << datacenterIdShift) | (workerId << workerIdShift) | sequence;}/*** @param lastTimestamp 上次生成ID的时间截* @return long 当前时间截* @描述 阻塞到下一个毫秒,直到获取到新的时间截* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/protected long tilNextMillis(long lastTimestamp){long timestamp = timeGen();while(timestamp < lastTimestamp){timestamp = timeGen();}return timestamp;}/*** @return long 当前时间(毫秒)* @描述 返回以毫秒为单位的当前时间* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/protected long timeGen(){return System.currentTimeMillis();}//==============================================测试========================================public static void main(String[] args) {SnowflakeIdWorker idWorker = null;try {idWorker = new SnowflakeIdWorker(0, 0);} catch (IllegalAccessException e) {e.printStackTrace();}for (int i = 0; i < 10; i++) {long id = idWorker.nextId();System.out.println(id+"\t"+String.valueOf(id).length());}}}
雪花算法的工程落地
糊涂工具包:
非常爽,专门干小而美的事情
官网地址:
https://github.com/looly/hutool/,在hutool-captcha即图片验证码实现中就包含雪花算法的实现,如果要用全家桶,就引入hutool-allpom.xml
【只使用雪花算法】
xxxxxxxxxx<denpendency><groupId>cn.hutool</groupId><artifactId>hutool-captcha</artifactId><version>4.6.8</version></denpendency>【使用hutool-all】
xxxxxxxxxx<denpendency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.0.1</version></denpendency>
使用雪花算法的项目搭建
pom.xml
xxxxxxxxxx<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-captcha</artifactId><version>4.6.8</version></dependency><dependency><groupId>com.atlisheng</groupId><artifactId>03-common</artifactId><version>1.0-SNAPSHOT</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency></dependencies>启动类
xxxxxxxxxxpublic class IDApplication {public static void main(String[] args){SpringApplication.run(IDApplication.class,args);}}ID工具类
使用糊涂工具包生成的包括雪花算法【但是没用默认的机器id和数据中心id生成id,使用的是本机IP,细节要研究糊涂工具包源码】
xxxxxxxxxxpackage com.atlisheng.cloud.utils;import cn.hutool.core.lang.Snowflake;import cn.hutool.core.net.NetUtil;import cn.hutool.core.util.IdUtil;import lombok.extern.slf4j.Slf4j;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;/*** @author Earl* @version 1.0.0* @描述 核心还是hutool工具包的IdUtil类,里面有很多生成各种ID的算法,这里只是对IdUtil生成雪花算法的又一层封装* @创建日期 2023/12/04* @since 1.0.0*/public class IdGeneratorUtilWithSnowflakeByHuTool {private long workerId = 0L;private long datacenterId = 1L;private Snowflake snowflake = IdUtil.createSnowflake(workerId,datacenterId);// @PostConstruct是java自带的注解,用途是被注解的方法,在对象加载完依赖注入后执行。此注解是在Java EE5规范中加入的,// 在Servlet生命周期中有一定作用,它通常都是一些初始化的操作,但初始化可能依赖于注入的其他组件,所以要等依赖全部加载完再执行。// 与之对应的还有@PreDestroy,在对象消亡之前执行,原理差不多,这里不做过多介绍public void init(){try{log.info(NetUtil.getLocalhostStr());//192.168.200.1//获取本机的workerIdworkerId = NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());log.info("当前机器的workerId:{}",workerId);//当前机器的workerId:3232286721}catch (Exception e){e.printStackTrace();log.warn("当前机器的workerId获取失败:{}",e);//如果获取不到机器id为workerId手动生成一个,避免workerId没有值,具体的含义看文档workerId = NetUtil.getLocalhostStr().hashCode();log.warn("手动生成的workerId:{}",workerId);}}/*** @return long* @描述 这个是使用默认本机Id和数据中心Id生成的雪花算法ID* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public synchronized long snowflakeId(){return snowflake.nextId();}/*** @param workerId* @param datacenterId* @return long* @描述 这个方法是指定机器Id和数据Id生成的雪花算法ID* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public synchronized long snowflakeId(long workerId,long datacenterId){Snowflake snowflake = IdUtil.createSnowflake(workerId, datacenterId);return snowflake.nextId();}/*** @return {@link String }* @描述 生成UUID去掉-的字符串* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public String simpleUUID(){return IdUtil.simpleUUID();}/*** @return {@link String }* @描述 生成最纯净版的UUID,即带-的* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public String randomUUID(){return IdUtil.randomUUID();}/*** @param args* @描述 工具方法测试* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/public static void main(String[] args) {IdGeneratorUtilWithSnowflakeByHuTool idGenerator = new IdGeneratorUtilWithSnowflakeByHuTool();log.info(String.valueOf(idGenerator.snowflakeId()));//1731649814501916672log.info(idGenerator.simpleUUID());//3493f90896d346659e3c5e54c035f75dlog.info(idGenerator.randomUUID());//75a40940-fb39-4b80-9810-555ccff3ebc7}}前端控制器
这里面的线程池就本例来说就是整活,以后可能会接触到
xxxxxxxxxx("/id")public class IDController {private IdGeneratorUtilWithSnowflakeByHuTool idGenerator;/*** @return {@link CommonResp }* @描述 测试通过一个线程池获取多个雪花算法生成的ID* @author Earl* @version 1.0.0* @创建日期 2023/12/04* @since 1.0.0*/("/create")public CommonResp generateId(){//生成含5个线程的线程池,线程池使用之后要立刻关ExecutorService threadPool = Executors.newFixedThreadPool(5);//意思是模拟20个请求,每个请求都通过线程池去获取雪花算法生成的idfor (int i = 0; i < 20; i++) {/*** 执行效果(只展示一部分)* 1731652083855261706* 1731652083855261707* 1731652083855261708* 1731652083855261709* 1731652083855261710* 1731652083855261711* 1731652083855261712* 1731652083855261713* 1731652083855261714* 1731652083855261715* */System.out.println(idGenerator.snowflakeId());}threadPool.shutdown();return new CommonResp(200,"snowflake");}}
【启动效果,这个机器ID似乎是用本机的IP生成的,不是使用0的机器ID和0的数据中心ID生成的】

【控制台id生成情况】
只展示了部分
xxxxxxxxxx1731652083855261706173165208385526170717316520838552617081731652083855261709173165208385526171017316520838552617111731652083855261712173165208385526171317316520838552617141731652083855261715
雪花算法的优缺点
优点
毫秒数在高位,毫秒内自增序列在低位,整个ID都是趋势递增的
不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成地 ID性能也非常高
可以根据业务特性灵活分配bit位,非常的灵活
缺点
依赖机器时钟,如果机器时钟回拨,会导致重复ID生成
单机上递增,如果设计到分布式系统,每台机器上的时钟不可能完全同步,有时候会出现不是全局递增的情况,该缺点可以认为无所谓,一般分布式ID值要求趋势递增,不会要求严格递增,90%的需求都只要求趋势递增
一般公司用雪花算法不用考虑时钟问题,如果非要要求有两家公司彻底解决了时钟回拨问题,并对雪花算法进行了优化,一个是百度开源的分布式唯一ID生成器UidGenerator、另一个是美团点评分布式ID生成系统Leaf,参考这两个进行雪花算法的时钟问题的同步
UUID
UUID.randomUUID().toString()生成一个32位的字符串,UUID【Universally Unique Identifier】的标准形式,包含32个16进制数字,以连字符分为字段,形式为8-4-4-4-12的36个字符【32个16进制数字+四个连字符,示例:2a007166-17a6-4394-b588-bb418ea15750】优点:肯定不重复,性能非常高,本地生成,没有网络消耗,jdk自带,只考虑唯一性的情况下已经够用,关键是无序,入数据库的性能比较差,id自增的情况下mysql的b树会生成的更好
缺点:
无序,无法看出UUID间的生成顺序,不能生成递增有序的数字
且比较长,分布式ID一般都会作为主键,mysql官方推荐主键越短越好,UUID每一个都很长,不推荐作为主键入数据库
拿UUID作为主键,会在特定的环境中存在一些问题【mysql官方说的如果主键太长,次级索引会使用更多的空间,强烈推荐使用短主键】
分布式ID一般作为主键,主键包含索引,mysql的索引是通过b+树实现的,因为UUID是无序的,为了查询的优化,每次新的UUID数据插入都会对主键地域的b+树进行很大的修改,会导致一些中间节点产生分裂,也会白白创造很多不饱和的节点,大大降低数据库插入的性能
五个分布式ID硬性要求只满足唯一性要求
数据库自增主键
单机的情况下可以使用,分布式系统有问题
数据库自增ID机制的原理是通过数据库自增ID和mysql数据库的replace into实现的,replace into和insert类似,不同点在于replace into先尝试插入数据到表中,如果发现表中已经有了相同主键或相同唯一索引的记录,就先删除原记录,再插入新数据,replace into的含义是插入一条记录,如果表中唯一索引的值遇到冲突则替换老数据】
代码
REPLACE INTO t_test (stub) values('b');反复执行会将此前相同唯一性约束的'b'的记录删掉,然后再重新插入相同stub字段属性值的记录,不同的是自增主键自加1,第一次为1,b,第二次会显示2,bxxxxxxxxxxCREATE TABLE t_test(id BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,stub CHAR(1) NOT NULL DEFAULT '',UNIQUE KEY stub (stub))SELECT * FROM t_test;REPLACE INTO t_test (stub) values('b');SELECT LAST_INSERT_ID();创建以上这个表,通过唯一约束字段,使用自增主键来生成对应的ID肯定是唯一且自增的,比UUID好,多满足了一个有序的条件,可以通过代码
SELECT LAST_INSERT_ID();查出来当前自增主键的值作为生成的唯一ID【小厂用这种方式就足够了,不需要处理分布式高并发场景,但是搞不定电商金融系统】缺点,高并发情况下,mysql服务器扛不住,可能发生宕机的情况,mysql服务器一旦宕机,自增主键生成不了,会发生非常严重的问题,所以这种数据库自增ID机制不适合做分布式ID,分布式系统使用这种机制一定要配置mysql集群,而使用mysql集群且做分布式ID生成服务器,会导致系统的水平扩展比较困难,比如最开始只有一台mysql机器做分布式ID的生成,但是这时候需要再加一台,为了保证主键的唯一性,需要将第二台机器的初始ID值设置的远超第一台,这样长时间两台机器的主键都不会重复,但是如果要添加100台mysql服务器,此时每台服务器都要进行这样的设置会变得非常复杂,难以实现【更别说分表分库扩容会带来非常多的麻烦】
数据库压力大,每次获取ID都需要读写一次数据库,非常影响性能,不符合分布式ID中服务器低延迟和高QPS的要求,高并发情况下要去从数据库获取ID,是非常影响性能的
基于redis生成全局id的策略
redis是单线程的【redis6已经支持多线程了】,天生保证原子性,可以使用原子操作INCR和INCRBY来实现全局ID的生成
缺点:和MYSQL一样在Redis集群的情况下同样需要设置不同redis服务器的初始值和步长,同时key也需要设置有效期,使用redis集群能够增加生成主键的吞吐量,又要防止配置ID生成逻辑防止单点故障,又要设置哨兵宕机情况下的反应,非常的麻烦,系统不需要redis使用这种方案生成ID还需要单独引入redis集群,宕机以后ID的单增要求也无法保证了
应用举例:一个redis集群中有5台redis【A、B、C、D、E】,初始化每台redis的值分别为1、2、3、4、5,步长设置为5;每台Redis生成的ID分别为
A:1、6、11、16、21
B:2、7、12、17、22
C:3、8、13、18、23
D:4、9、14、19、24
E:5、10、15、20、25
附录
注意:@Slf4j在lombok包里面,此外还需要导入log4j、slf4j-api、slf4j-log4j12依赖才能记录方法,且两个slf4j版本需要保持一样
xxxxxxxxxx<!--注意:@Slf4j在lombok包里面,此外还需要导入log4j、slf4j-api、slf4j-log4j12依赖才能记录方法--><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>RELEASE</version><scope>compile</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.30</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.30</version></dependency>Math.abs取绝对值
HashMap的values方法
HashMap 中所有 value 值所组成的 collection
xxxxxxxxxximport java.util.HashMap;class Main {public static void main(String[] args) {// 创建一个 HashMapHashMap<Integer, String> sites = new HashMap<>();// 往 HashMap 添加一些元素sites.put(1, "Google");sites.put(2, "Runoob");sites.put(3, "Taobao");System.out.println("sites HashMap: " + sites);// 返回所有value值组成的视图System.out.println("Values: " + sites.values());}}values() 方法可以与 for-each 循环一起使用,用来遍历迭代 HashMap 中的所有值
xxxxxxxxxximport java.util.HashMap;class Main {public static void main(String[] args) {// 创建一个 HashMapHashMap<Integer, String> sites = new HashMap<>();// 往 HashMap 添加一些元素sites.put(1, "Google");sites.put(2, "Runoob");sites.put(3, "Taobao");System.out.println("sites HashMap: " + sites);// 访问 HashMap 中所有的 valueSystem.out.print("Values: ");// values() 返回所有 value 的一个视图// for-each 循环可以 从view中访问每一个value值for(String value: sites.values()) {// 输出每一个valueSystem.out.print(value + ", ");}}}
字符串的子串和子序列
子串指原始字符串的一个连续子集
子串在相对顺序不变的基础上还要求首尾字符之间的字符不能缺失
子序列指原始字符串的一个子集
子序列要求字符之间的相对顺序不能变
高级面试看基于工程背景的技术选型方案能力